
It’s pretty impossible to track manually when a file is changed in a folder or list of folders. Even if you have a good strategy, you’ll miss files, make mistakes, and, even worse, lose time doing it. That’s why automation exists, and OneDrive for Business “When a file is modified” is here to help. It will keep an eye on the folder or a list of folders and trigger with the file and some metadata when it’s changed. After that, you can perform the actions on the file, but notice that we’re getting a copy of the file, not the actual file that exists in OneDrive for business. It’s s subtle thing and, for our purposes, will be the same, but if you want to make changes to the file, for example, then you need to access the original file to do them.
Let’s see how to find it and how to use it.
Where to find it?
You can search for the “When a file is modified” trigger or click “OneDrive for Business”.
Select “When a file is modified”
Here’s what it looks like.
You can take advantage of some advanced properties that we’ll explore a bit more below.
Let’s see how to use it.
Usage
Using it is pretty simple. You point it to a folder, and it will return the file and some metadata. For full metadata, you need to use the "When a file is modified (properties only)" trigger. If you know the file identifier, you can include it here, but it’s rare and error-prone to be helpful to do it this way. It’s better to pick the folder from the list of folders in the UI.

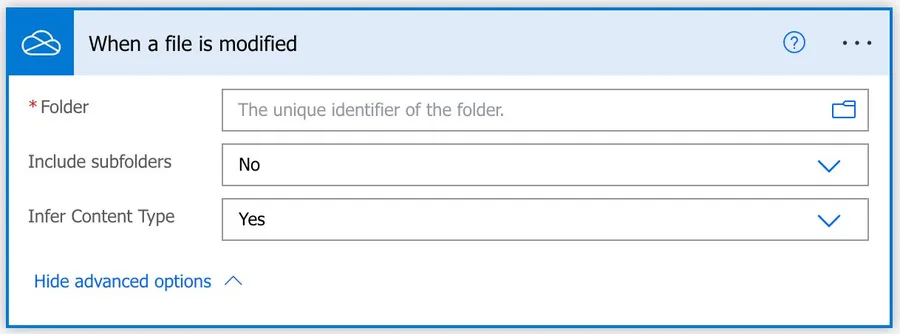
As mentioned before, this trigger has advanced options, so let’s explore them now.
Include subfolders
This option is quite handy when detecting files since we are not limited to the folder we select. You can pick this option if you want to see changes to the file in the whole tree of folders underneath the one you chose.
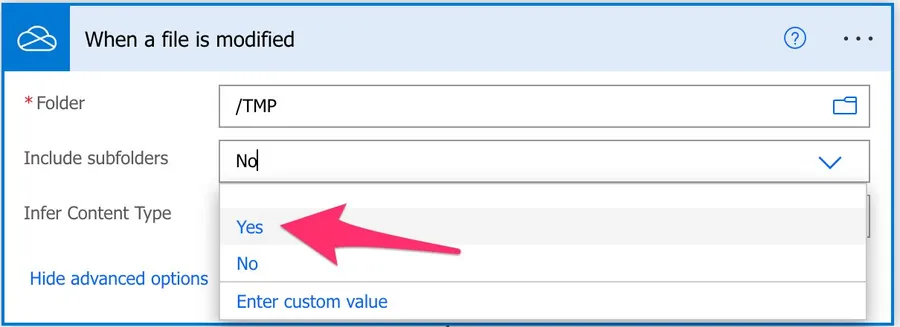
Be aware that files get changed a lot, so enabling this option will trigger this Flow a lot. You need to think about two essential things when allowing this:
- Do I have enough runs to accommodate this? There are limitations to the number of runs, so it’s important not to exhaust them with unnecessary triggers.
- Do I have good filters after the Flow is triggered? It’s uncommon to need all files changed, especially if we’re looking at subfolders, so think if you have enough excellent filters, only files you want to get through the following sections of the Flow.
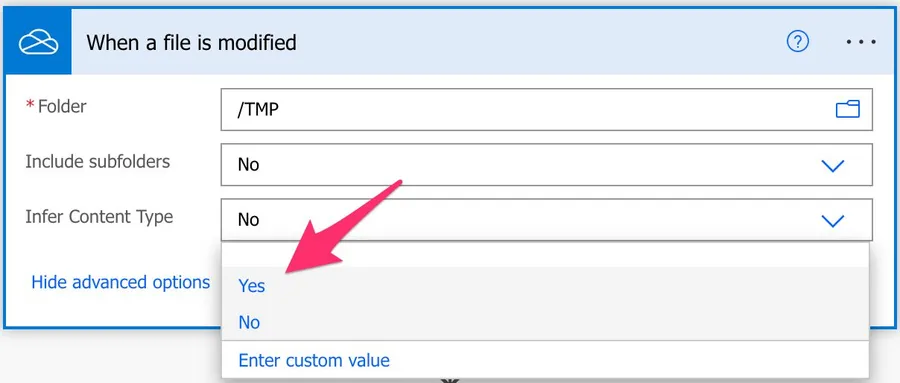
Infer Content Type
If you want to use the “content-type” then you can enable “Infer Content Type,” which will return based on the file’s extension.
For example, if your file is an Excel Workbook (xlsx), then the content-type will be “application/vnd.openxmlformats-officedocument.spreadsheetml.sheet” (I know it’s ugly, but that’s the convention). You can get the content-type from here:
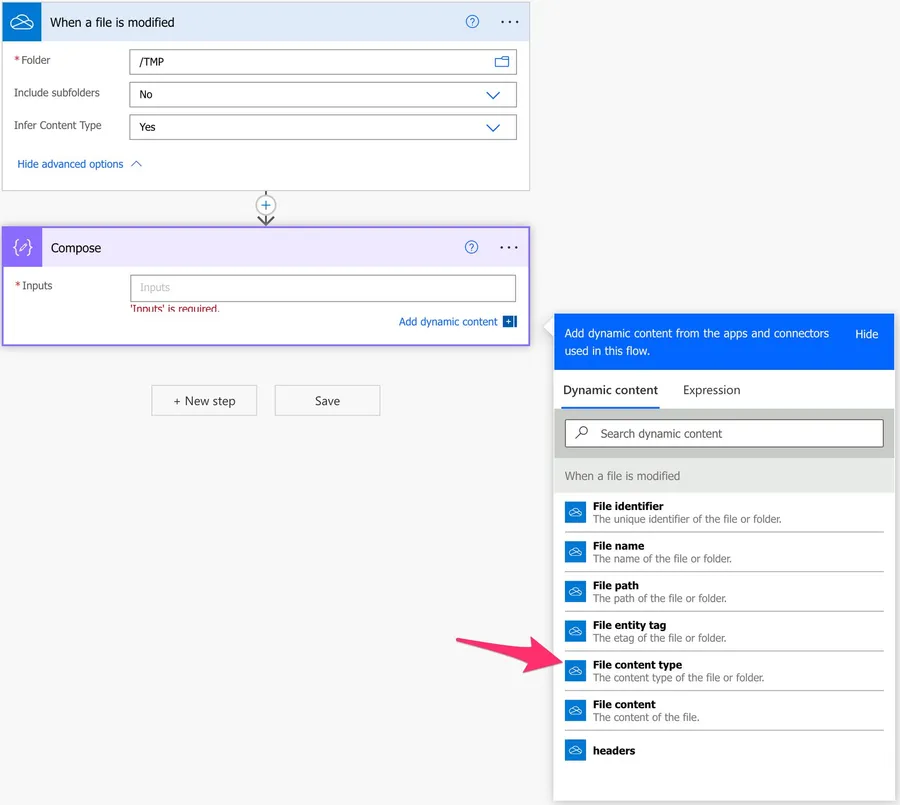
You rarely need this, but I wanted to include it in case you need it for some reason.
Outputs
The trigger returns metadata from the file, but if you need the entire file’s metadata, you need to use the “When a file is modified (metadata only)” trigger.

If you need more metadata after the trigger, you can use the “Get File Metadata” action with the “File Identifier” you got in the trigger.
Limitations
It only supports files smaller than 50 MB. Remember that the file will be returned so that bigger files would imply longer transfer times.
Recommendations
Here are some things to keep in mind.
Don’t use this for synchronization
I see many questions regarding synchronization between locations, and the “When a file is modified“ trigger is an excellent target to catch items that need replication. But I would strongly advise you not to do it. Synchronization of items is an amazingly complex topic in computer science, and we are all super when something doesn’t synchronize properly. If the trigger fails, data will be out of sync, and Power Automate won’t rerun it. If the data is changed on the destination list, you already have a problem that will only worsen over time.
Name it correctly
The name is super important in this case since we can get the trigger from anywhere and with anything. Always build the name so that other people can understand what you are using without the need to open the action and check the details.
Always add a comment
Adding a comment will also help avoid mistakes. Indicate what you’re expecting, why the Flow should be triggered, and what the data will be used. It’s essential to add comments when limiting the trigger with some custom rules since these are not prominent in the UI, and people may get confused as to why the Flow doesn’t trigger when it’s simply a rule preventing it from doing so. It’s essential to enable faster debugging when something goes wrong.
Finally, let people know why you’re choosing the parameters you configured. For example, why do you select that folder if you have a folder defined? It may make sense now, but not in a few months.
An automated trigger is better than a scheduled one
Sometimes people are tempted to use scheduled triggers that pool the resources once in a while. This way, they can control when the information is fetched and save much Power Automate "triggers" if their quota is low. However, even if it isn't, it may be more efficient to do batch tasks than once by one. I understand, and in some cases, I can agree, but it brings a lot of difficulties in the process. For example, you may need to keep track of what changed from the last run until this one so that some things may get lost. Also, you're forcing something to happen periodically, even if there's no data.
I always recommend using these "automatic" triggers instead, where they trigger one by one, but only when there's data, so you're always sure you get something to do. Also, debugging triggers that parse a single data point instead of multiple simultaneously is much easier. If something fails on one, then you can fix the Flow and repeat the process. But while parsing multiple ones, things can get a lot harder.
Back to the Power Automate Trigger Reference.
Photo by Nick Fewings on Unsplash



No comments yet
Be the first to share your thoughts on this article!