
Parsing emails is super boring so having a Flow that takes care of downloading attachments and sorting them is a huge timesaver. I have an article that discusses how to do that, and you find it here, but today let’s push ourselves a bit more. Since the body of the email is HTML (not always, but we’ll consider only HTML emails for this article), download a file from a link in an email, even if they are not attachments. Then, we’ll parse the body of the email, find links, try to follow them, and save any files that we get. Also, we’ll figure out the type of file and save it with the correct extension.
Parse HTML to find all links and download files
This solution template will find any link in an HTML string, find links and download all files associated with them, with premium connectors.
Thanks to @ lequocminh1 for getting in touch with this interesting challenge.
The Template
So let’s look at how to build a cool template to achieve this. If you don’t want to read further, here’s the solution template you can import with both Flows.
[su_icon_panel icon="icon: star" icon_color="gold" icon_size="48"] In order to make things generic I’ll provide a template that receives HTML and a file path and stores the file that we get from there. This template uses a premium action. I don’t have another solution yet to this, but I’ll publish a new template as soon as I can find one[/su_icon_panel]
The Strategy.
Since this template can be used in other places, we won’t bind it to an email. However, with the “Run Child Flow,” we can call this template everywhere we need it.
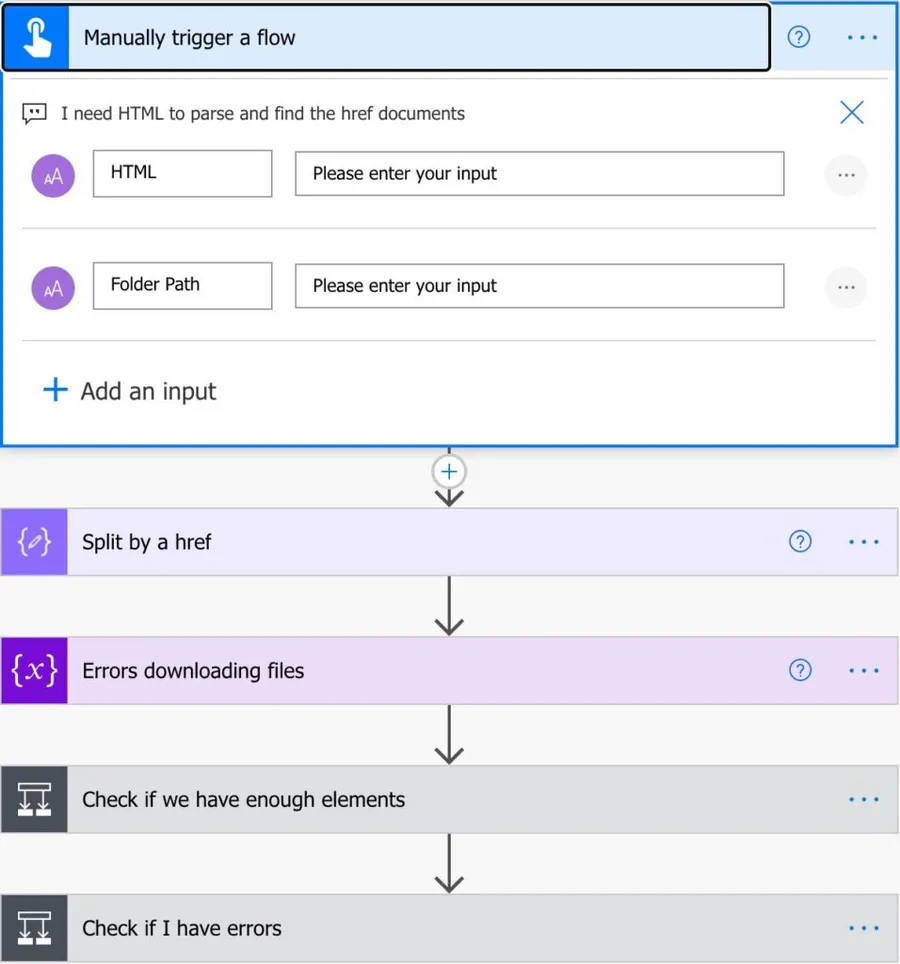
We have two inputs:
- The HTML string to parse
- The file path to save the file. We’ll use OneDrive for Business, but you can also use a SharePoint Site or Microsoft Teams to do this.
Now that we have what we need, we’ll do the following:
- First, split the HTML by “href”. This way, we’ll get an array with all the links.
- If we have more than 2 rows (at least one link), parse it.
- Finally, clean the link and download it.
That’s it. I’ll explain this action individually because it can cause some confusion.
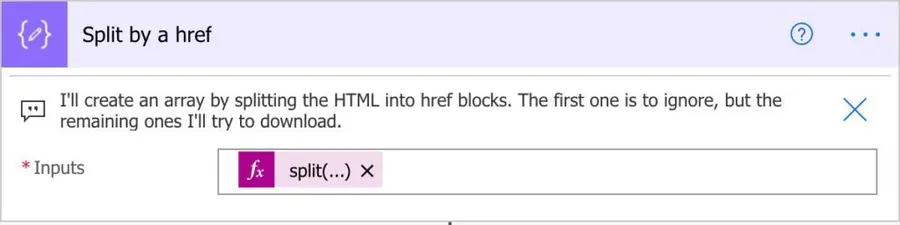
Split
The Split function is our best friend here to start breaking the data apart from for processing. We have a huge string of HTML code, and we need to find the href tags. If you’re not familiar with HTML, the links are always with the following syntax:
<a href="<URL>" ...>Text of the Link</a>
I’m oversimplifying here, but it’s not important to know in dept how links work.
Let’s imagine that we have the following HTML:
...
<a href="https://manueltgomes.com">
...
<a href="http://twitter.com/manueltgomes">
...
We want to break everything into an array and clean it to get only the links. If we split the array by <a href with the following formula:
split(triggerBody()['text'],'<a href')
We get:
[0] - ...
[1] - ="https://manueltgomes.com/">...
[2] - ="http://twitter.com/manueltgomes">...
We can ignore the first row, and we have two more array items with the links we need. In future actions, we’ll clean the remaining HTML that is not necessary.
Error handling
I’ll initialize a new array variable that will be used to deal with errors.
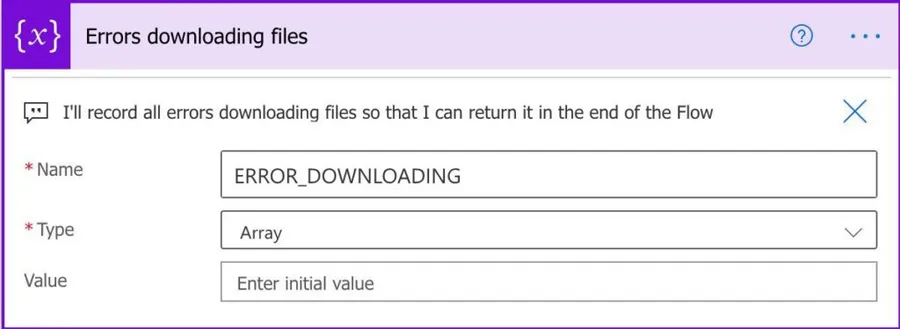
Since it’s important to do some error handling, we’ll collect all invalid downloads and errors during the Flow and return them at the end of the Flow. This way, we can collect them in the Flow that calls this one and deal with them if needed.
Parse the results
Now that we have the HTML split, we have two possibilities:
- First, we only have one row. Second, if this is the case, there are no links to parse.
- We have more than one row, so we have links to download.
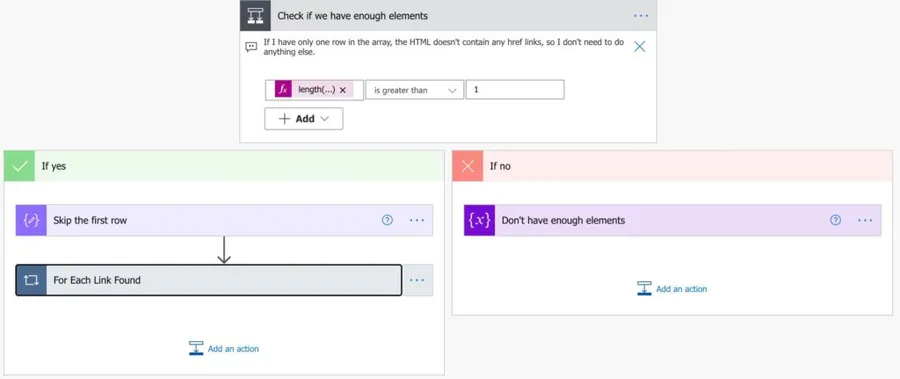
Just because we find links doesn’t mean that there’s something to download on the other side. But we’ll only know when we actually download and see what we get.
Skip the row
To ignore the first row, we’ll use the skip function. Here’s the formula:
skip(outputs('Split_by_a_href'),1)
The function will return an array starting at the position that you provide it. In our case, we want to ignore the first element of the array, so we’ll start in position 2. Don’t forget that the positions start at “0,” so we want to move forward at the second position, hence the “1”.
The array is now this:
[0] - ="https://manueltgomes.com/">...
[1] - ="http://twitter.com/manueltgomes">...
Now that we have only the links let’s parse them.
Parse the links
Let’s go to the meat of the template. Now we’ll use an ”Apply to Each” action that gets all the array elements that we filtered in the previous step and prepare them to download.
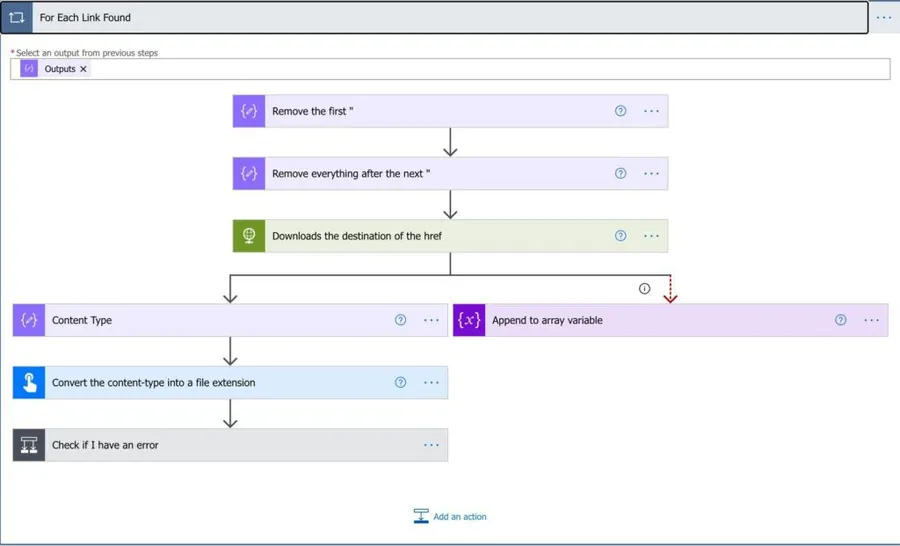
First, we remove the beginning of the tag. Here’s the formula:
substring(item(),add(indexOf(item(),'"'),1))
We use 4 functions here:
- item function to get the current item in the ”Apply to Each” action
- indexOf function to find the first occurrence of the quote
- Add function to increase the position by one.
- Substring function to get the string that we need.
Let’s bring the array again:
[0] - ="https://manueltgomes.com">...
[1] - ="http://twitter.com/manueltgomes">...
We want to fetch the first instance of the first quote and get the string after that since we don’t want to include the quote we need to add one to the position to ignore it.
So looking at the first, we get:
https://manueltgomes.com/"...
Now let’s remove the end of the link. To do that, we’ll use the same strategy but starting from zero until the next quote. Here’s the formula:
substring(outputs('Remove_the_first_"'),0,indexOf(outputs('Remove_the_first_"'),'"'))
As you can see, we’ll use the output of the previous action. With this, we get:
https://manueltgomes.com/
The download
Now we’re ready to do the download.
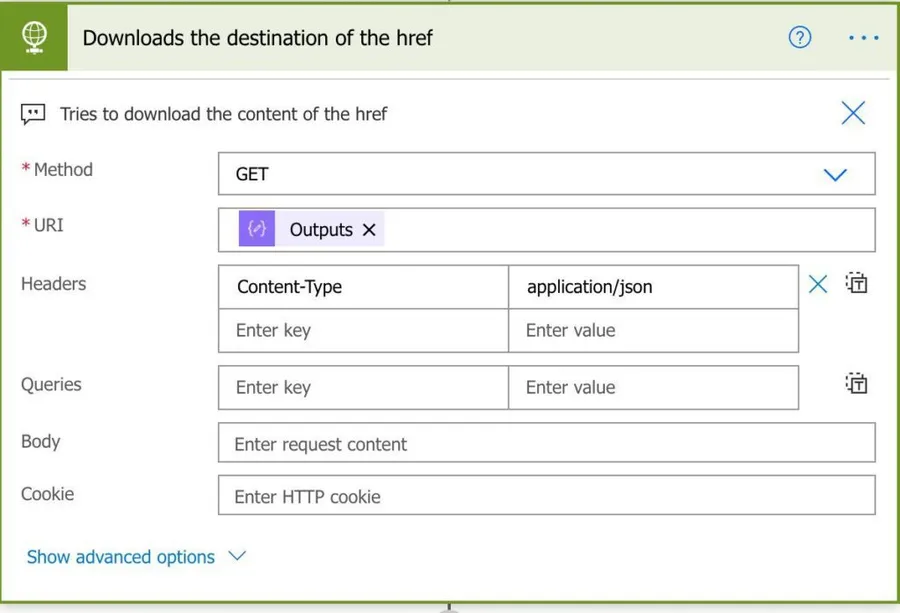
As I mentioned before, this is a premium action. I’ll try to find another solution for this but, in the meantime, that’s the one we have.
Parse the download
After the HTTP action, we have two outcomes. The first is we don’t manage to download anything. It can be for several reasons so that the HTTP action will return an error. We’ll deal with it by adding to the array an error message. This is represented above by the right branch

Looking at the left branch, we get something useful downloaded, so let’s save it. The HTTP returns a lot of stuff to us, and one that is super important is the content-type type of information that we retrieved. There’s a lot, but we need this to save the file in the correct format. Since the content-type is something like image/png (for a PNG file), we need to translate this into .png.
To do it, we have another Flow that we call using the “Run Child Flow” action that we built with one thing in mind. It will get a content-type and will return an extension.
Saving the file
Let’s save the file.
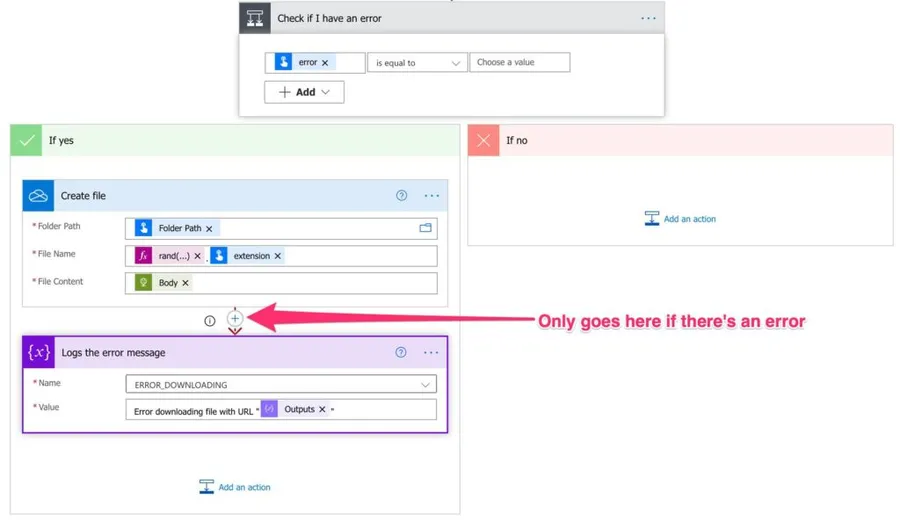
As you can see above, the OneDrive For Business “Create File” action has:
- The “Folder Path” that we got in the trigger
- The “File Name” is generated with a random number using the “rand” function and the extension from the previous step.
- The “File Content” is the result of the HTTP action.
There’s an interesting thing that we’re doing here, where we only add to the error array if there’s an error saving the file. This will enable us to have an exception to send to the user once the Flow finishes running.
Return
Now that we have everything, let’s return something.
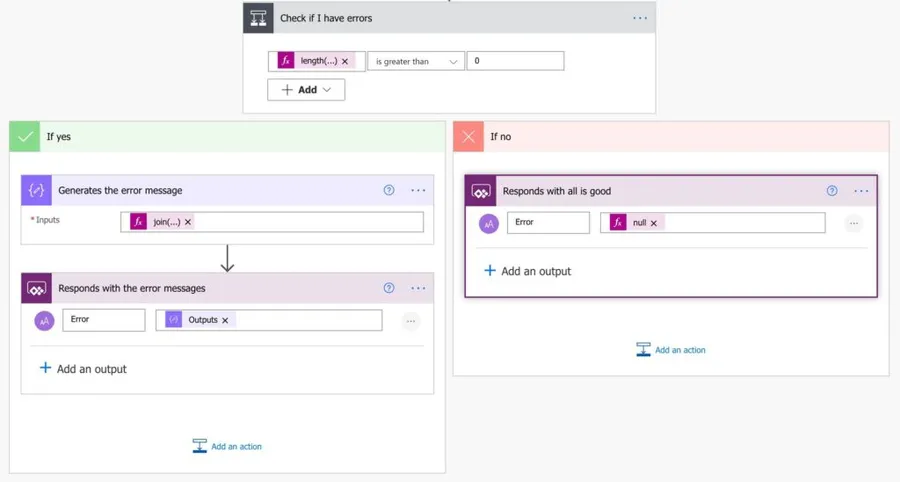
We have two possibilities. If we don’t have values in the array, we will need to send the reply to the user with the list of the errors. To do so, we’ll use the join function.
join(variables('ERROR_DOWNLOADING'),',')
This will generate a string with all the error messages separated by commas. If we don’t have errors, we return the error message.
What about the email part?
We mentioned in the beginning that we want to download a file from a link in an email, but up until now, we don’t mention the email part. I did this on purpose because I wanted to show you that the main part is parsing the HTML. With this template, you can use it for emails or for any other HTML parsing needs that you may have. I’ve also included in the solution a template for the email, and it’s as simple as this:
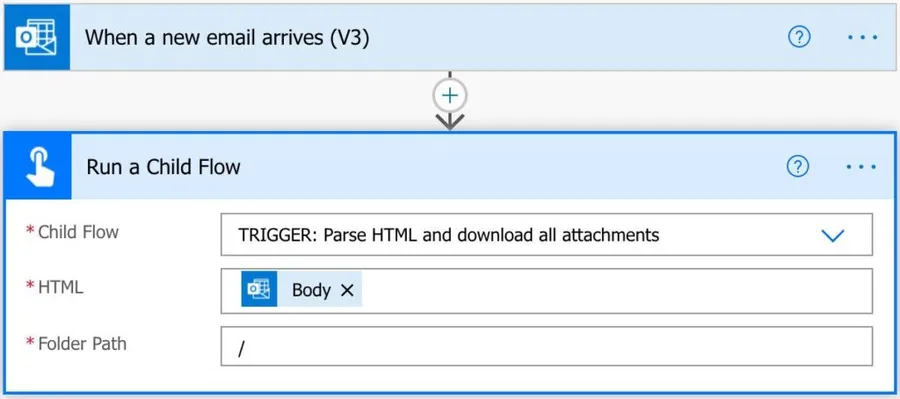
There are a lot of advantages to doing it this way.
- We can have multiple triggers calling the same Flow. If you have multiple folders that you want to monitor, you only need to duplicate the 2 steps above, and you’re good to go.
- You can look at multiple services. So if you want to check your Gmail and Outlook, for example, you can. It’s all in the trigger.
- Any changes in the “Parse HTML and download all attachments” will be propagated to all Flows that call it.
Finally, let’s look at error handling. Since the “Parse HTML and download all attachments” returns an error, we can look at it and deal with the error.
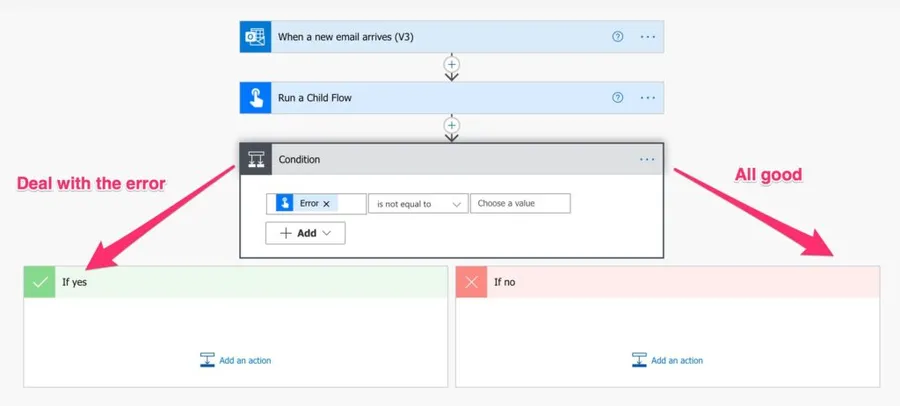
There are many ways to deal with errors, so I’ll leave it up to you on how you want to do it.
Final thoughts
Parsing HTML is hard, so it’s possible that the Flow won’t work for all cases. My objective is to show you how to download a file from a link in an email while making things generic enough that you can download a file from any HTML code.
If you find any issues, please email me a sample of your HTML, and I’ll try to make this template better for everyone.
Photo by Florian Olivo on Unsplash



Thank you! I tried to import the template but i have the following error. "Something went wrong. Please try again later."
same here
I believe you have to import it as a solution, not as a flow. I am close on getting it imported but there are missing connection references that show up when I try to do it.
In the parse the results section, In the Control - Condition part what´s the formular being use with Length function?
Good catch! It's the length of the array variable that contains all the errors. We can proceed if there's no error (empty array). Here's the expression: length(variables('ERROR_DOWNLOADING'))
Thank you so much I appreciated it.
Hi Manuel, There are some images missing from your article making it hard to understande for someone new to Power Automate such as myself. Could you perhaps take a look? This is my html after splitting it. Any suggestion on how to extract the correct URL? They are always preceded by a safelinks URL. I need the part after "originalsrc=\" and remove all the rest before and after the URL. I tried to shorten it and add some whitespace for readability. I actually only need the first 2 URLs with "www.url.com". The rest are privacy notices or a download for adobe reader. [ "\r\n "=\"https://eur05.safelinks.protection.outlook.com/?url=https%3A%2F%2Fwww.url.com\originalurl1" originalsrc=\"www.url.com\originalurl1" shash=\"abcdefgh=\" target=\"_blank\"><b>Click here</b></a> "=\"https://eur05.safelinks.protection.outlook.com/?url=https%3A%2F%2Fwww.url.com\originalurl2" originalsrc=\"www.url.com\originalurl2" shash=\"abcdefgh=\" target=\"_blank\"><b>Click here</b></a> "=\"https://eur05.safelinks.protection.outlook.com/?url=http%3A%2F%2Fwww.adobe.com%2Fproducts%2Facrobat%2Freadstep2.html" originalsrc=\"http://www.adobe.com/products/acrobat/readstep2.html\" shash=\"ghijkl=\" target=\"_blank\"><b>Adobe Reader</b></a> "=\"https://eur05.safelinks.protection.outlook.com/?url=https%3A%2F%2Fwww.sdworx.be%2Fnl-be%2Fcorporate%2Ffooter%2Fprivacy" originalsrc=\"https://www.sdworx.be/nl-be/corporate/footer/privacy\" shash=\"qsdfgh=\">Privacy</a> "=\"https://eur05.safelinks.protection.outlook.com/?url=https%3A%2F%2Fwww.sdworx.be%2Fnl-be%2Fcorporate%2Ffooter%2Fdisclaimer" originalsrc=\"https://www.sdworx.be/nl-be/corporate/footer/disclaimer\" shash=\"gjhkhkg=\">Disclaimer</a> ] Thank you! Joachim
Hi Manuel In the "Parse the links" part, right in "For Each Link found" in the field where it reads "*Select and output from previous steps", I should click in add dynamic content and once the same display the list of options I should choose "Skip the first row - Outputs" is that correct? In the next steps "Remove the first*" I´m using the function substring(item(),add(indexOf(item(),'"'),1)) and in "remove everything after the next" I´m using the function substring(outputs('Remove_the_first_"'),0,indexOf(outputs('Remove_the_first_"'),'"')) but when I save my progress the Flow checker comes up with the message "Remove everyting after the next"..."Correct to incluide a valid reference to 'Remove_the_first" 'for the input parameter(s) of action ¨Remove_everything_after_the_next"'. Do you know what that means? and how it can be fixed?
Dear Manuel, Thank you for your input in various articles, it has helped me a lot in my learning journey. Similarly I am trying to give back by helping others in the community forums. You mentioned that you wanted to find a way to download a file via a link without using Premium connectors. Did you ever succeed? I came across a situation which needed that. Thank you in advance, Koen
Hi Koen, Great job giving back. I'm happy you're doing it. Can you share some links so that everyone can check your work? Not yet, to be honest. I have a potential solution, but I need time to prepare it. Unfortunately, I didn't have the time recently to do it, but I really want to release it to the community. I'll report back as soon as I have something, but if you find a suitable solution, please let me know! Thanks!
also looking for something without premium, i got the trial and still awaiting it to apply to account, tried importing your template and got missing dependencies, new_sharedoffice365_3fd16 and new_sharedonedriveforbusiness_2be66 is the imported somewhere else? by your article could we do all the steps manually or do we need the template?
when importing template as premium, missing dependencies. new_sharedoffice365_3fd16 new_sharedonedriveforbusiness_2be66 any idea what to do here?
I have the same error and I'm not sure what to do at this point.
Hi, i have the same error when i try to import the template (as a flow not a solution ;) Any idea to do ?
I have the same issue @Joshua Berstein and Laurent Sanchez face. Some dependencies are missing. Any solution here?
works okay.