
Today I answered a question in the Power Automate Community, and one of the members posted an interesting question. How to parse a CSV file and get its elements? I see this question asked a lot, but the answer is always to use external component X or Y, and then you can do it.
New template to parse a CSV file without premium connectors
I wrote a new template, and there's a lot of new stuff. You can now define if the file has headers, define what's the separator character(s) and it now supports quotes. It's a huge upgrade from the other template, and I think you will like it. You can find the detail of all the changes here. I'll leave both links below so that you can follow the steps in this article, but if you want to jump to the new one, go right ahead.
Although some of the components offer free tiers, being dependent on an external connection to parse information is not the best solution. You may not be able to share it because you have confidential information or have the need to parse many CSV files, and the free tiers are not enough. Finally, we depend on an external service, and if something changes, our Power Automate flows will break.
The motivation
I want to answer this question completely. This will benefit the overall community, so I decided to build a CSV parser using only Power Automate's actions. The overall idea is to parse a CSV file, transform it into a JSON, and collect the information from the JSON by reference. For example, if we have the file:
name,date
Manuel, 12-12-2020
Gomes, 13-12-2020
Teixeira, 12-1-2020
I inserted the space on purpose, but we'll get to that. We'll get the following JSON:
[
{
"name": "Manuel",
"date": " 12-12-2020"
},
{
"name": "Gomes",
"date": " 13-12-2020"
},
{
"name": "Teixeira",
"date": " 12-1-2020"
}
]
And then, we can do a simple "Apply to each" action to get the items we want by reference. Looks nice.
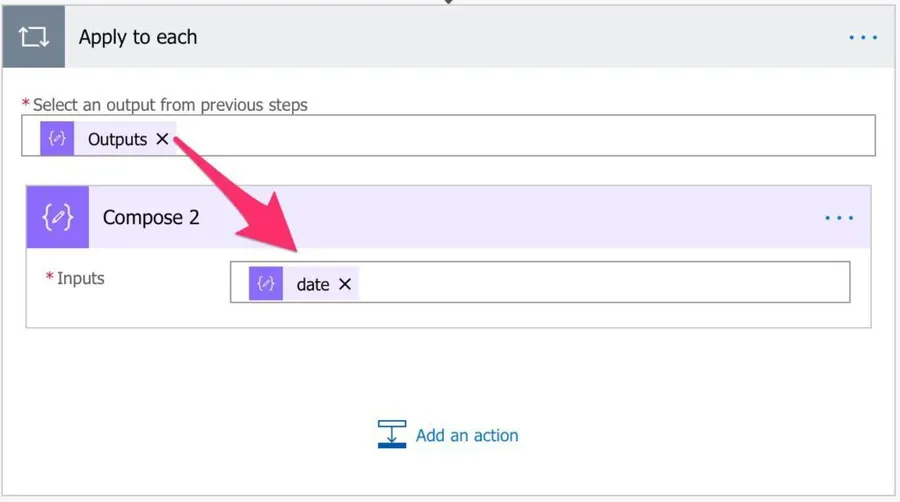
The template
The template may look complicated, but it isn't. I'll explain step by step, but here's the overview.

You can trigger it inside a solution by calling the "Run Child Flow" and getting the JSON string. If you don't know how to do it, here's a step-by-step tutorial.
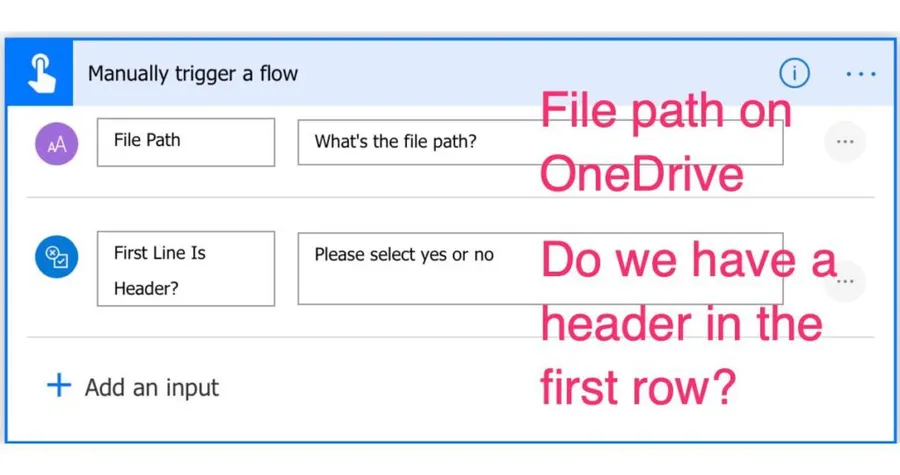
The trigger
The trigger is quite simple. We need to provide two parameters:
- The path of the file in OneDrive. With this, we make the Power Automate flow generic
- It's important to know if the first row has the name of the columns. With this information, we'll be able to reference the data directly.
Fetching the file
With the parameter in the trigger, we can easily fetch the information from the path.

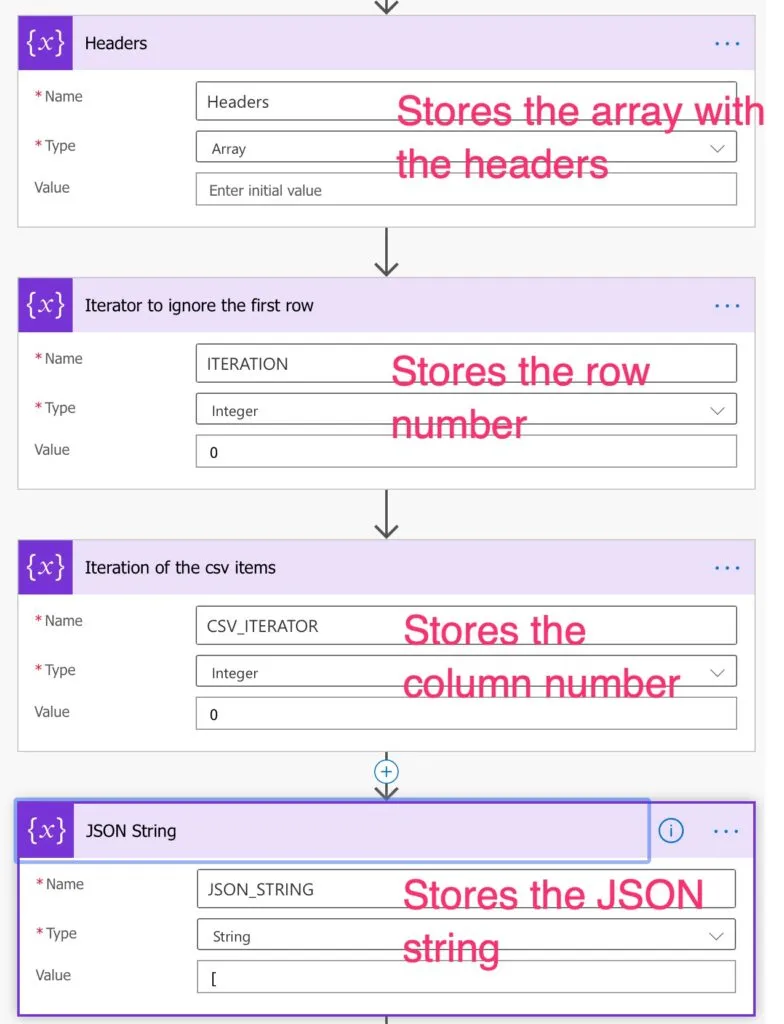
The variables
The variables serve multiple purposes, so let's go one by one.
Each Row
In this one, we break down the file into rows and get an array with the information.
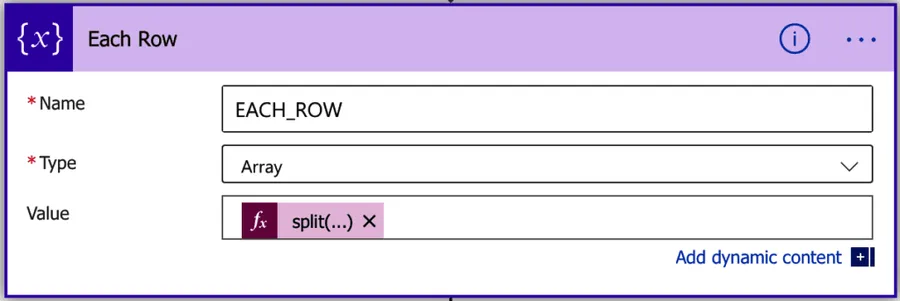
The formula is quite simple:
split(outputs('Get_file_content_using_path')?['body'],'')
It's not an error in the return between '. There would be the temptation to split by "," but, for some reason, this doesn't work. If you apply the formula above, you'll get:
[
"name,date",
"Manuel, 12-12-2020",
"Gomes, 13-12-2020",
"",
"Teixeira, 12-1-2020"
]
Looks good.
Helper variables
I use the other variables to control the flow of information and the result. You'll see them in action in a bit.
The parsing
OK, let's start with the fun stuff. Here we want to:
- Fetch the first row with the names of the columns.
- Check if we have at least two lines (1 for the column names and one with data)
- Get an array for each row separated by ','
- Check if the array is not empty and has the same number of columns as the first one. If it has more or less, then we cannot do the mapping, for example:
[
"name,date",
"Manuel, 12-12-2020", this one doesn't have a column name
"Gomes, 13-12-2020",
"",
"Teixeira, 12-1-2020"
]
- Get the row elements.
- Build the JSON element, for example:
{
"name": "Manuel",
"date": " 12-12-2020"
}
- Add that to a JSON string (variable created above)
Looks complex? Well, a bit, but at least makes sense, right?
Check the column names and min requirements
The first two steps we can do quickly and in the same expression. To check the number of elements of the array, you can use the "length" function:
length(variables('EACH_ROW'))

Parsing the headers and checking the information
Now that we know that we have the headers in the first row and more than two rows, we can fetch the headers. To do so:
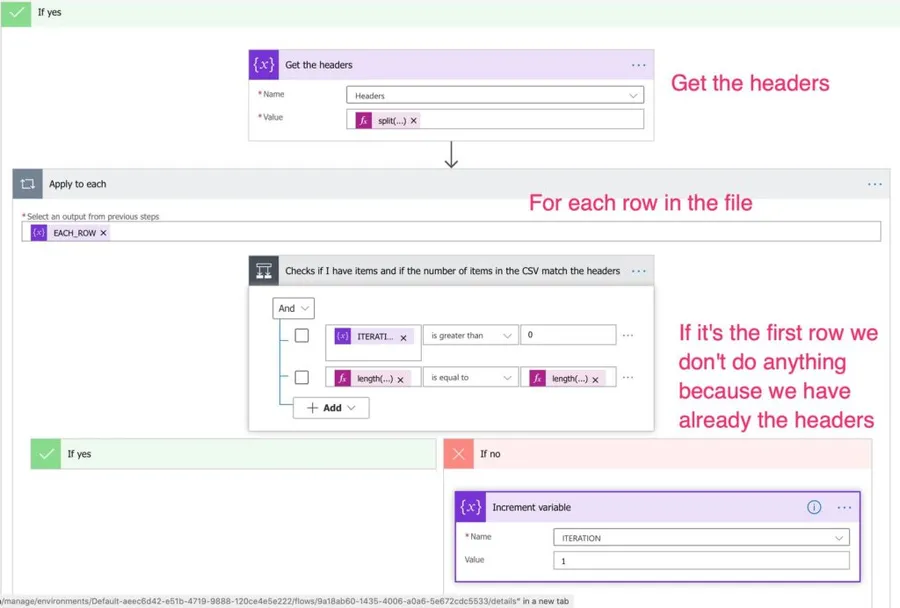
split(variables('EACH_ROW')[0],',')
We get the first element and split it with the "split" function by our separator to get an array of headers. Then we start parsing the rows. If it's the beginning, then we don't do anything because it contains the headers, and we already have them. To check if the row has the same number of elements as the headers (second clause of the if), we have the following formulas: Several elements in the headers:
length(variables('Headers'))
Several elements in the current item:
length(split(items('Apply_to_each'),','))
Now let's parse the information.
Parsing the remaining rows
First, we get the array with the elements of the row split by ','
split(items('Apply_to_each'),',')
Then we upgrade the iterator since we're already parsing another row.
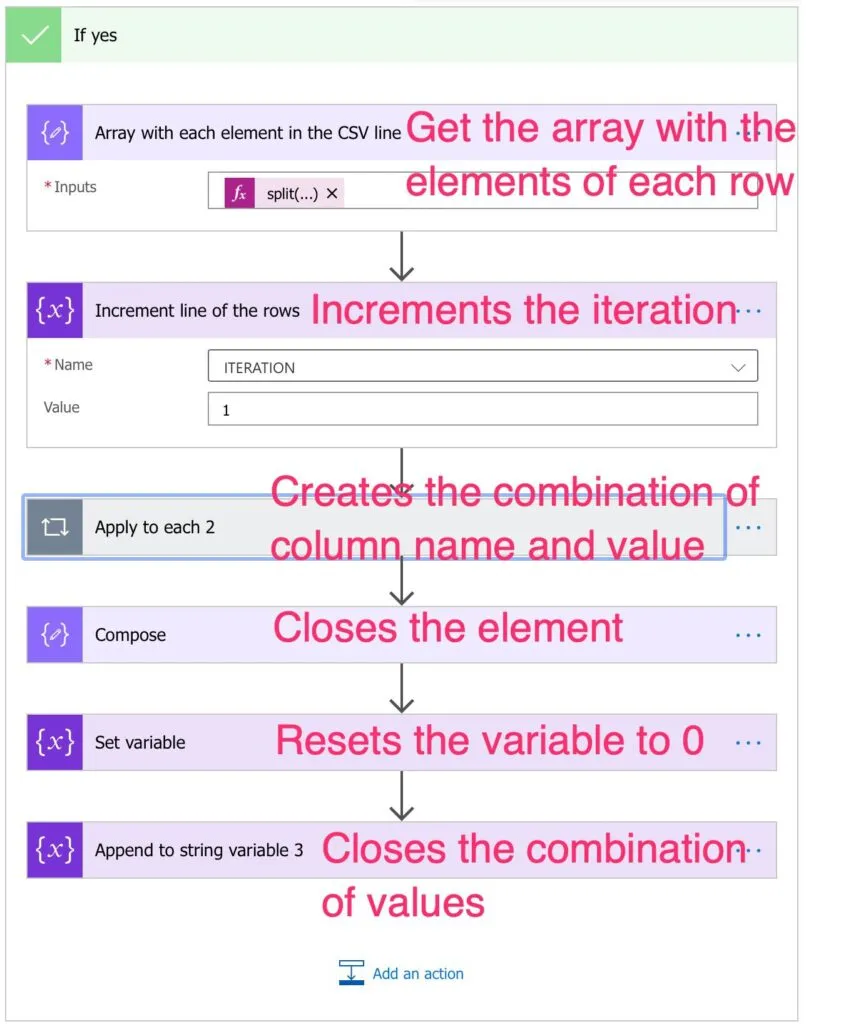
The application to each is a little bit more complicated, so let's zoom in.
Generating the element
Since each row has multiple elements, we need to go through all of them.
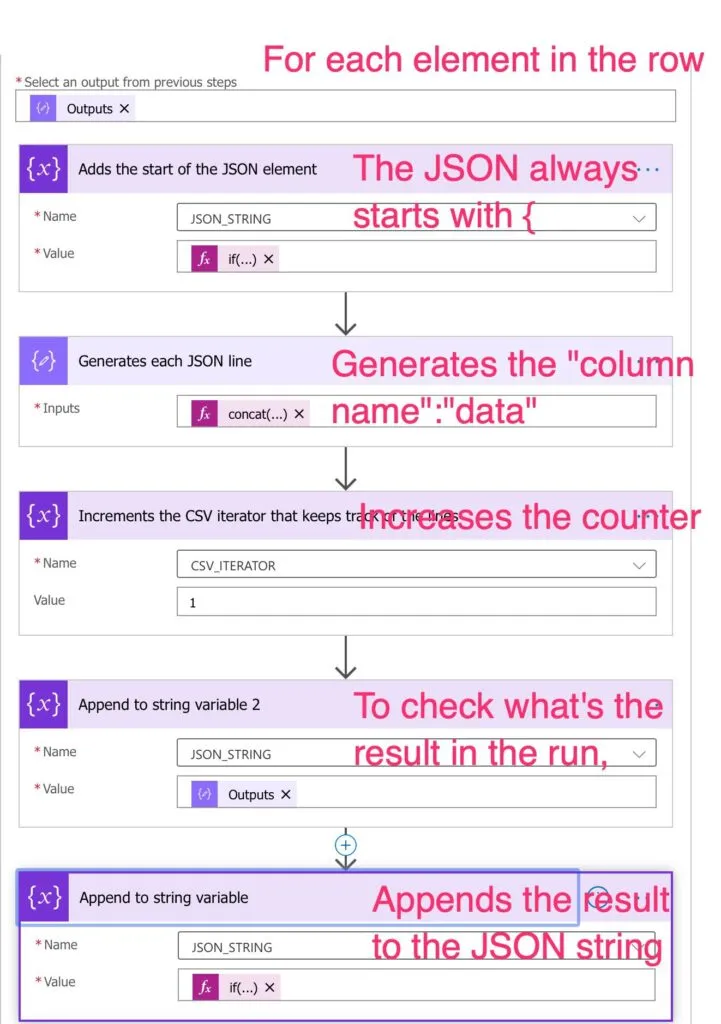
First, let's add the start of the value with an if statement. This will check if we're in the beginning and add an "{" or nothing.
if(equals(variables('CSV_ITERATOR'),0),'{','')
The formula is a concatenation using the "concat" function:
concat('"',variables('Headers')[variables('CSV_ITERATOR')],'":"',items('Apply_to_each_2'),'"')
Let's break it down:
- Add a
"(double quote) - Go to position X of the headers and get the name and the current item. Generates
{"name": "Manuel"
We need to increase the element by one. The next column to parse and corresponding value. So that we can generate the second column and the second record:
"date": " 12-12-2020"
Now let's bring them together:
if(equals(length(outputs('Array_with_each_element_in_the_CSV_line')),variables('CSV_ITERATOR')),'}',',')
Here we're checking if we're at the end of the columns. If we are, we close the element with }. Otherwise, we add a "," and add the next value. In the end, we get:
{
"name": "Manuel",
"date": " 12-12-2020"
}
Closing the loop
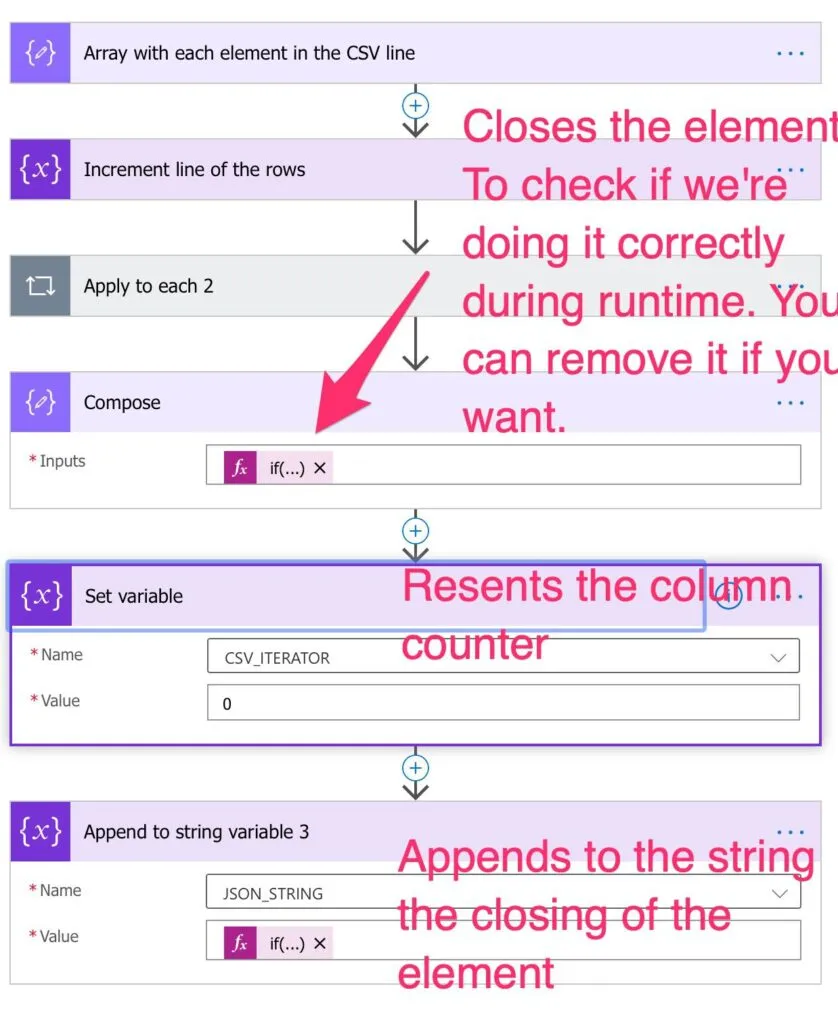
Since it's so complicated, we added a "Compose" action with the formula so that, in run time, we can check each value and see if something went wrong and what it was. Finally, we reset the column counter for the next run and add what we get to the array:
if(equals(length(variables('EACH_ROW')),variables('ITERATION')),']',',')
If it's the last line, we don't add a "," but close the JSON array "]"
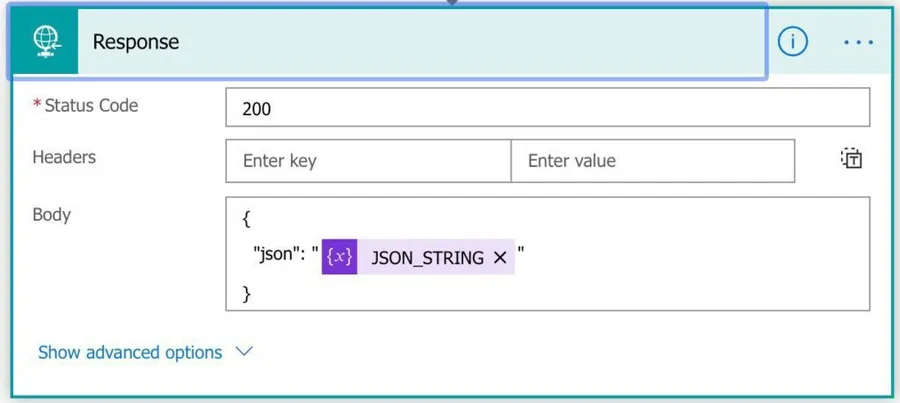
Return the JSON
All we need to do now is return the value, and that's it.
Final Thoughts
Please note that you can, instead of a button trigger, have a "When an HTTP request is received" trigger. With this, you can call this Power Automate flow from anywhere. Both the HTTP trigger and the "Response" action are Premium connectors, so be sure that you have the correct account. If you want to call this, all you need to do is the following:
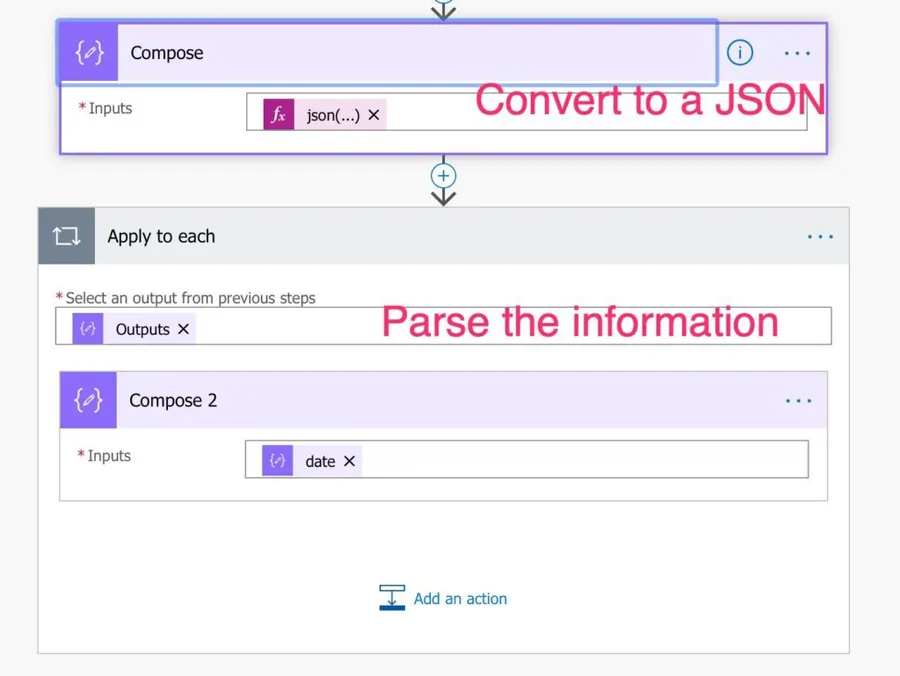
Call the Power Automate flow and convert the string into a JSON with the "json" function:
json(triggerBody()['text'])
Then all you have to do is go through all values and get the information that you need. Again, you can find all of this already done in a handy template archive so that you can parse a CSV file in no time. There are other Power Automate flows that can be useful to you, so check them out. Download this template directly here. If you don't know how to import a template, I have a step-by-step here.
Photo by AbsolutVision on Unsplash



I am obviously being thick, but how do I process the result in my parent flow?
Hey Lee, You can use a "Parse JSON" that gets the values and creates an array and use a "For Each" to get each value. Makes sense? Cheers Manuel
I am attempting to apply your solution in conjunction with Outlook at Excel: 1) Trigger from an email in Outlook -> to be saved in OneDrive - > then using your steps for a JSON. 2) After the steps used here, is it possible to create one JSON that continues to be updated. The end goal here is to use the JSON to update content in Excel (through Power Query). What sort of editions would be required to make this work? Do you have any other advice that I might be able to refer to? Thank you.
Hey! If you want to persist, the JSON is quite simple. You can add all of that into a variable and then use the created file. Tick the "replace if exists," so the new version will replace the old one. Makes sense? Cheers Manuel
Hey! If you want to persist the JSON is quite simple. You can add all of that into a variable and then use the created file to save it in a location. Tick the "replace if exists," so the new version will replace the old one. Makes sense? Manuel Cheers Manuel
I keep getting the same error message InvalidTemplate. Unable to process template language expressions in action 'Each_Row' inputs at line '1' and column '6184': 'The template language function 'split' expects its first parameter to be of type string. The provided value is of type 'Object'. Please see https://aka.ms/logicexpressions#split for usage details.'. I downloaded your flow file and still get the same problem. Any Ideas?
Hey Caleb, Are you getting this issue right after you upload the template? That's really strange. If there's sensitive information, just email me, and we'll build it together. CHeers Manuel
I have the same problem. Did you find out with Caleb what te problem was? Thank you in advance.
How did you solve this? I have the same problem here!
Hi Anna, I re-imported the template and did a bunch of testing and I think it's all working: <img src="https://manueltgomes.com/wp-content/uploads/2020/11/F48D3BC5-112B-4159-9409-B7B83C9997D2.png" alt="Flow Result" /> To be extra-sure I've uploaded that exactly Flow again. You can find it <a href="https://manueltgomes.com/wp-content/uploads/2020/11/ParseCSVFile_20201125090419.zip">here</a>. Can you please give it a try and let me know if you have issues. Thanks
Hello, I am currently in a tricky spot at the moment. I would like to convert a json i got (from your tutorial) and put it into an online excel worksheet using power automate. So i am trying to parse the Json file to create an array, and iterating through that array and adding every row into the excel document. Currently what i have is a really simple Parse Json example ( as shown below) but i am unable to convert the output data from your tutorial into an object so that i can parse the Json and read each line. Any Tips? { "type": "object", "proprerties": { "Title": { "type": "String" }, "Employee Name": { "type": "String" } } } Or am i looking at things the wrong way? Hopefully that makes sense Thank you
Hey Lin, Your definition doesn't contain an array; that's why you can't parse it. Can you please send me the Power Automate print-screens to my email, and we'll build it together :). Cheers Manuel
Wow, this is very impressive. Thanks so much for sharing, Manuel!
Hey Nairolf, Thanks a lot! I really appreciate the kind words Cheers Manuel
Hi, I don't think you included the if value of the JSON_STRING variable in the Apply to each 2.
Hi dyl, You're absolutely right, and it's already fixed. Thanks a lot for reaching out. Manuel
I was following your "How to parse a CSV file" tutorial and am having some difficulties. In my flow every time I receive an email with an attachment (the attachment will always be a .csv table) I have to put that attachment in a list on the sharepoint. But in the variable "Each_row" I can't split the file because it is coming to me as a base64 file. Any idea how to solve? Thank you!
HI Anna, Have you imported the template or build it yourself? I'm finding it strange that you're getting that file and not a JSON to parse. If you're not comfortable posting details here,, please feel free to email me with your Flow to try to help you further. Manuel
Thanks for the template, much appreciated.
Hi Rob, You're more than welcome :) Cheers Manuel
Hi Manuel, I have followed this article to make this flow automate. Here is scenario for me: Drop csv file into Sharepoint folder so flow should be automated to read csv file and convert into JSON and create file in Sharepoint list. Everything is working fine. CSV is having more than 2500 rows so when I am testing this with till 500 rows then it is taking time but working perfectly. But when I am going to test this flow with more than 500 records like 1000, 2000 or 3000 records then flow is running all time even for days instead of few hours. Lastly, canceled the flow because it is running for days and not completed the flow. Message had popped at top of the flow that: "Your flow's performance may be slow because it's been running more actions than expected since 07/12/2020 21:05:57 (1 day ago). Your flow will be turned off if it doesn't use fewer actions.Learn more" Learn More link redirecting to me here: https://docs.microsoft.com/en-us/power-automate/limits-and-config Would you like to tell me why it is not working as expected if going to test with more than 500 rows? Thanks.
Hi Ashutosh, Before we try anything else let's activate pagination and see if it solves the issue. <img src="https://manueltgomes.com/wp-content/uploads/2020/12/Screenshot-2020-12-10-at-15.47.56.png" alt="Pagination" /> Can you please check if and let me know if you have any questions? Cheers, Manuel
Hi Manuel, Sorry, I am not importing data from Excel file and Excel file reading is having this pagination activation settings . But I am doing with CSV file and CSV file is not having such kind of settings to do pagination activation. Please suggest. It is taking lots of time. Any clue regarding Power Automate plans which will be restricting to do this? Thanks, Ash
Manuel, this is fantastic, the flow is great. But I do received an error which I am now trying to solve. InvalidTemplate. Unable to process template language expressions in action 'Generate_CSV_Line' inputs at line '1' and column '7576': 'The template language expression 'concat('"',variables('Headers')[variables('CSV_ITERATOR')],'":"',items('Apply_to_each_2'),'"')' cannot be evaluated because array index '1' is outside bounds (0, 0) of array. Please see https://aka.ms/logicexpressions for usage details.'. Maybe you can navigate me in the solution how it can be solved?
I have found an issue. The delimiter in headers was wrong. Works perfect. Fantastic.
Awesome! Well done!
Hi Rostyslav, For some reason, the variable "Headers" is empty. Can you look at the execution and check, in the step that fills in the variable, what is being filled-in or if there's an error there? Cheers Manuel
Is there any way to do this without using the HTTP Response connector? I ask because this is a Premium connector and I'm trying to do this using only the Free/Standard options available to me through my organization.
Not yet, but I'm working on finding a solution and explaining it here with a template. It's indeed a pity that this is a premium connector because it's super handy. Cheers Manuel
Hi Manuel, Thanks very much for this - it's really great. I'm having a problem at the "Checks if I have items and if the number of items in the CSV match the headers" stage - it keeps responding as false. I am using a sample dataset with about 7 records. I wonder if you'd be able to help? Thank in advance, James
Hi James, Glad the tutorial is helping you :). You're referring to this part, right? <img src="https://manueltgomes.com/wp-content/uploads/2021/01/Screenshot-2021-01-13-at-08.51.18.png" alt="" /> This is a 2 part validation where it checks if you indicated in the trigger if it contains headers and if there are more than 2 rows. Since you have 7 rows, it should be ok, but can you please confirm that you're providing 1 or 0 for true and false, respectively. Please let me know if it works or if you have any additional issues. Manuel
Hi Manuel, Sorry not that bit - it's the bit 2 steps beneath that - can't seem to be able to post an image. It's AND( Iteration > 0, length(variables('Headers')) = length(split(items('Apply_to_each'),','))) It keeps coming out as FALSE and the json output is therefore just "[" I am selecting "true" at the beginning as the first row does contain headers. Thanks for all your help in advance, James
Hi James, Does your previous step "split(variables('EACH_ROW')[0],',')" returns an array? Can you please check if the number of columns matches the number of headers. For example: Header 1, Header 2, Header 3 row 1, row 2 The condition will return false in that step. What steps does 2 things: 1. Checks if there are headers 2. Checks if the header number match the elements in the row you're parsing. Can you please take a look and please let me know if you can fix the issue? Cheers Manuel
Manuel, how do you avoid the "\r" being returned for the final entry in each row? If I have a simple CSV with two columns (Account,Value), this is what's returned: [ "Account,Value\r", "Superman,100000\r", "Batman,100000000\r", "Green Lantern,50000\r", "Wonder Woman,125000" ]
Hey! I think this comes from the source CSV file. Can you please paste here a dummy sample of your first 3 rows so that I can check? One workaround to "clean" your data is to have a compose that replaces the values you want to remove. Something like this: replace(<variable name>, '\r', '') Can you please try it and let me know? Cheers Manuel
Hi Richard, I had the same issue. I found out that MS Excel adds this \r line ending to csv-files when you save as csv. I found a comment that you could avoid this by not using Save as but Export as csv. https://answers.microsoft.com/en-us/msoffice/forum/msoffice_excel-mso_mac-mso_o365b/csv-line-endings/2b4eedaf-22ef-4091-b7dc-3317303d2f71 Best, Christoph
My first comment did not show up, trying it again. It seems this happens when you save a csv file using Excel. You should use 'export as' instead of 'save as' or use a different software to save the csv file.
I'm having this same issue. The pictures are missing from "You should have this:" and "Let's make it into this:". Can you repost?
Thank you, Manuel! I want so badly for this to work for us, as we've wanted PA to handle CSV files since we started using it. We were able to manage them, somewhat, with workflow and powershell, but workflow is deprecated now and I hate having to do this in PS since we are using PA pretty regularly now. My issue is, I cannot get past the first 'get file content using path'. No matter what I've tried, I get an error (Invalid Request from OneDrive) and even when I tried to use SharePoint, ('Each_Row' failed - same as Caleb, above). Am I just missing something super simple? Nobody else here seems to have that initial error when trying to grab the file from OneDrive. I would rather use SharePoint, though (having CSV created using SSRS and published to SharePoint) Thank you, again! In theory, it is what I'm looking for and I'm excited to see if I can get it to work for our needs! ~ Laura
Hi Laura, Please email me your Flow so that I can try to understand what could be the issue. We'll figure this out don't worry. Cheers Manuel
This only handles very basic cases of CSVs - ones where quoted strings aren't used to denote starts and ends of field text in which you can have non-delimiting commas. I think that caveat should probably be put in the article pretty early on, since many CSVs used in the real world will have this format and often we cannot choose to avoid it! Appreciated the article nonetheless. Also random note: you mentioned the maintaining of spaces after the comma in the CSV (which is correct of course) saying that you would get back to it, but I don't think it appears later in the article.
Hi Harvey, Excellent points, and you're 100% correct. I wrote this article as a v1, but I'm already working on the next improvement. Please keep posted because I'll have some cool stuff to show you all. Cheers Manuel
Thank you! I was actually (finally) able to grab the file from OneDrive, pull it through this process and populate a SharePoint list with the JSON array. (Yay!!). The one thing I'm stumped on now is the '\r' field. It will not populate SharePoint. I've tried using the replace method both in the Compose 2 (replace(variables('JSON_STRING'),'\r','')) and in the Parse JSON actions ( replace(outputs('Compose_2'),'\r','') ) but still couldn't get it to populate that "string" field. The flow runs great and works on the other fields, though! Thank you! Laura
Hi Laura, Well done!!!! Almost there!! 😀 The \r is a strange one. Can I ask you to send me a sample over email (manuel@manueltgomes.com) so that I can try to replicate it? Also, I've spent some time and rebuilt from scratch a Flow. It solves most of the issues posted here, like text fields with quotes, CSV with or without headers, and more. It's quite complex, and I want to recheck it before posting it, but I think you'll all be happy with it. I'll post it in the coming days and add a warning to the article. I'll test your file already with the new Flow and see if the issue is solved. Cheers Manuel
Excellent information, I will try it and let you know how it goes. Thank you in advance
This sounds just like the flow I need. However, I can't figure out how to get it into a Solution? I understand that the flow that should launch this flow should be in the same solution. But I can't import instant flows into a solution... Do I have to rebuild it manually? Or can you share a solution that includes this flow?
Hey! Good point, and sorry for taking a bit to reply, but I wanted to give you a solution for this issue. The short answer is that you can't. I know it's not ideal, but we're using the "Manually trigger a Flow" trigger because we can't use premium connectors. But don't worry, we can import the "whole" solution 😀. I created a template solution with the template in it. You can import the solution (Solutions > Import) and then use that template where you need it. You can find it <a href="https://manueltgomes.com/wp-content/uploads/2021/10/ParseaCSVSolution_1_0_0_2.zip">here</a>. Please give it a go and let me know if it works and if you have any issues.
Hi Manuel, I just came across your post. There is a more efficient way of doing this without the apply to each step: https://sharepains.com/2020/03/09/read-csv-files-from-sharepoint/
Hi Pieter, Indeed you're right. AWESOME! THANKS! :) I'll take a look and improve the template. Manuel
If anyone wants a faster & more efficient flow for this, you can try this template: https://powerusers.microsoft.com/t5/Power-Automate-Cookbook/CSV-to-Dataset/td-p/1508191 And if you need to move several thousands of rows, then you can combine it with the batch create method: https://youtu.be/2dV7fI4GUYU Together these methods could move 1000 CSV rows into SharePoint in under a minute with less than 30 actions, so you don’t waste all your account’s daily api-calls/actions on parsing a CSV.
If Paul says it, I'm sure it is a great solution :). I'll have to test it myself, but I take your word it works fine. I'll publish my findings for future reference. Thanks for posting better solutions. That's how we all learn, and I appreciate it.
First, thank you for publishing this and other help. It's been a god send. :). Second, I have a bit of a weird one you might want to tackle. The CSV I need to parse does not have a header row until row 8, row 9 to row 'x' are standard CSV layout based on the 'row 8' header. All other rows (1-7 and x+1 to end) are all "headername, data,". I'm trying multiple points of attack but so far, only dead ends.
Hi Manuel, I really need your help. Trying to change the column headers while exporting PowerBI paginated report to csv format. (Source report has different column names and destination csv file should have a different column name). Can this be done? I am not even a beginner of this power automate. I have used the Export to file for PowerBI paginated reports connector and from that I need to change the column names before exporting the actual data in csv format. Thanks in advance!