
I've mentioned this a lot in previous articles, but I want to go today into more detail about what a parallel branch is and how it's helpful to you. First, please note that this is not the same as concurrency. I go into a lot of detail regarding this in my "What is Concurrency Control?" article. Still, since both terms can be used interchangeably in other applications and platforms, it can be misleading. Concurrency is at the action level, while the parallel is at the global level as a rule of thumb. There's a lot more since they work differently in Power Automate, but I wanted to highlight this before going forward.
With that out of the way, let's go.
Where can I find it?
Parallel branches are not defined by a particular action or trigger since it's part of the "glue" that connects actions. If you've used Power Automate until now, I'm sure you've seen it already.
Let's see an example where we want to parallel two "Compose" actions. Here's how you can do it.
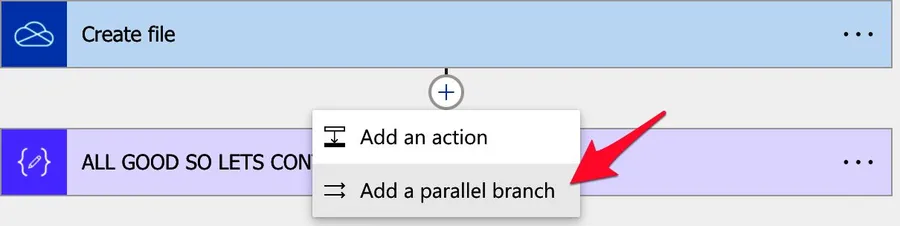
Power Automate will display another "branch" with the option to select actions to go in that branch. Select one and you'll see this:

Typical, you would add "sequential" tasks on Power Automate where each action will run after the other, but sometimes it is helpful to have parallel branches.
Why it's useful
There are two groups or types of parallel branches.
The first is to have tasks running in parallel to make your Flows run faster. For example, imagine fetching information from two SharePoint lists and adding them to another list. Then, you can run them in parallel instead of running the first SharePoint "Get Items" action, parsing it, and then running the second "Get items" action.
Tasks running sequentially:

Tasks running in parallel:

It's a lot that you save. Notice that the savings aren't literally since Power Automate has to deal with the paralyzation, but it's close to it. You will be limited by the slowest group of actions and not by the overall running time.
The second type is when you want different behaviors based on what happened. Again, it's a bit vague so let's use an example to illustrate the difference. Let's say that you want to create a file and something goes wrong. It's terrible that the Flow breaks and tasks are not executed, so we should think about what to do in these circumstances. For example, we could define a parallel branch, but the actions in that branch will only be performed if something goes wrong. You can find more details about this in my "Plan for errors and timeouts" article, but here's what we can do:
- Add a parallel branch.
- Add an action or more that deals with the errors.
- Change the error handling actions to run only if there's a timeout, fail or skip.
To do it, select the "add a parallel branch" option.
Add an action and select the 3 dots.

After that select, the "Configure run after" option.
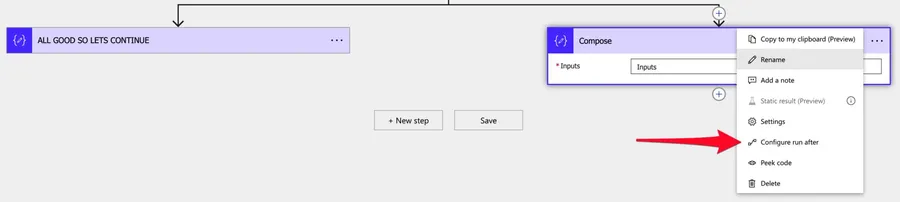
Select the "error" options.
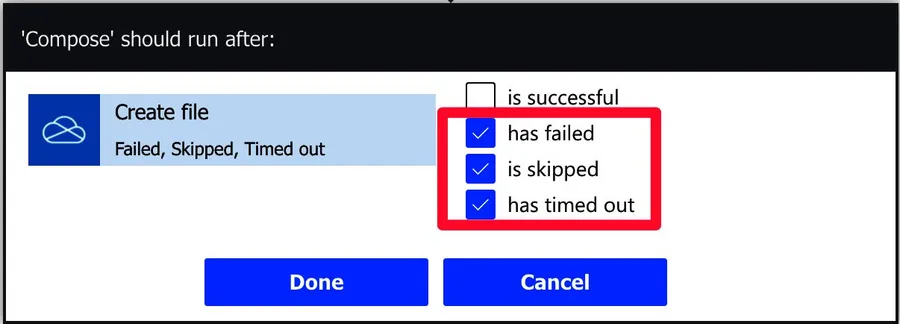
Notice that you get a "red" path indicating that we're only selecting the error options.

One may argue that these are not entirely "parallel" since they will run one or the other. It's true, but in this case, this strategy will allow you to deal with errors without having your Flow automatically failing when something goes wrong. When I say "deal with errors," it can be something as simple as sending an email to someone alerting them that something went wrong, but it can also be checking if the file already exists, deleting it, and trying to create it again.
It can be as straightforward or as complex as you want it to be.
Pitfalls
As always, some pitfalls are using a parallel branch. I'll name a few, but please feel free to interact on Twitter or email me with your feedback if you have others. It's always welcome.
We have no control over how Flow runs the actions for the parallel tasks. So if you're making the list A and list B into list C, you don't know if Flow will insert list A item 1 and list B item 1 or list A item 1 to 10 and then list B item 1. Since it's parallel, Flow will try to run both simultaneously, being the role, in this case of SharePoint, to deal with concurrency. If the destination is well equipped to deal with this, your items will all be inserted, but if you're using a file, for example, there's no guarantee that the items will all be saved to the file since we have two things "fighting" to save the data.
Another example of being careful is needing a particular order while inserting the data. As mentioned before, Flow will try to run both at the same time, and the destination will deal with that as best as it can, so there's no guarantee that the items will be inserted in a specific order. However, you can test it yourself, run a Flow twice, and compare the results. I'm sure you'll find differences in the order the data is inserted.
So don't use parallel tasks if:
- The order is important
- If you're using some persistence (database, file, service), that cannot deal with concurrent access properly.
A good rule of thumb is, if it's a database or service of any sort since there are already multiple people using them, you should be ok since they need to deal with parallelization. But if it' something like Excel, for example, where people can collaborate, but it was not built for multiple people accessing it simultaneously, you should be careful. Of course, it's an oversimplification, but keep this in mind.
Final thoughts
It's essential that you understand the path of your Flow and how it behaves if all goes well or something fails. But I strongly recommend using them for error handling, especially when you're doing tasks that change something. If they fail in the middle of the change, your Flow should react in any way to avoid issues, even if it's only to warn someone.
You can combine all strategies to have paths of your Flow that are parallel and others that deal with errors. You'll see a massive boost in time to run the Flow.
Photo by Will Suddreth on Unsplash



A glaring design omission is that there is no action to terminate a parallel branch. You can terminate the entire flow but not one branch.