
If you build any Flow, the chances are that it has an “Apply to Each” action. The action will parse the elements sequentially from an array. Multiple actions return arrays like SharePoint’s “Get Items,” for example. But you've also found that some Flows run slowly when there's a lot of data to parse, depending on the volume of data to parse.
Long-running Flows can impact your workflows, so let’s see how we can make things faster.
Parse multiples not only one
The strategy is simple. Why parse one item after the other when we can parse multiple at the same time? That's where the “Concurrency Control” comes into play. We can define the “degree of parallelism” and tell Power Automate how many we want to parse simultaneously, up to a max of 50.
Here’s how to do it, in the “Apply to Each” action, for example.
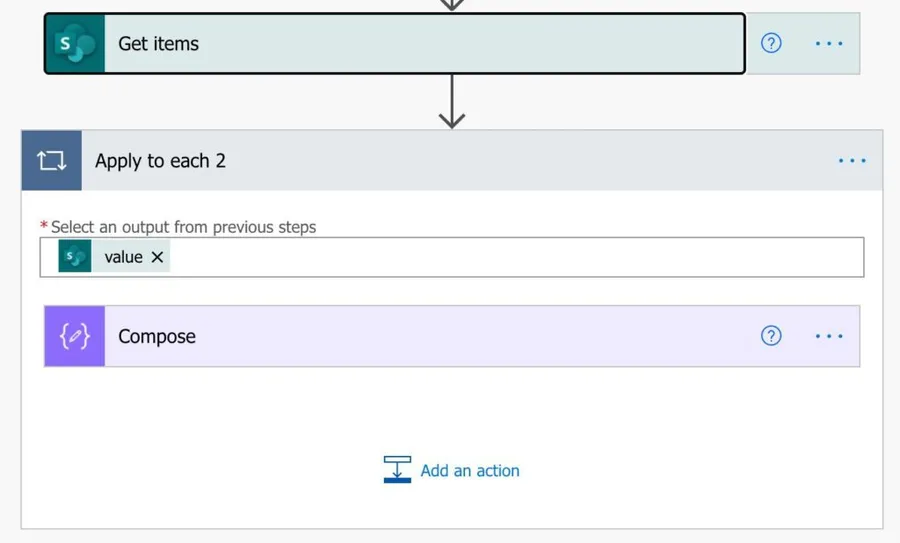
To access the “Concurrency Control,” go to the “Settings” of the “Apply to Each” action.
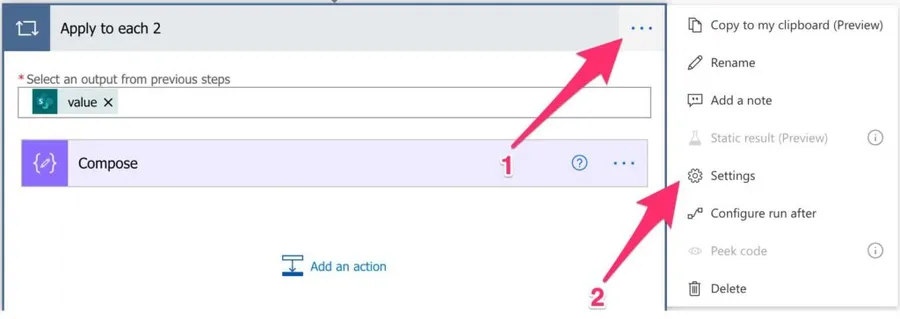
You’ll see the following:
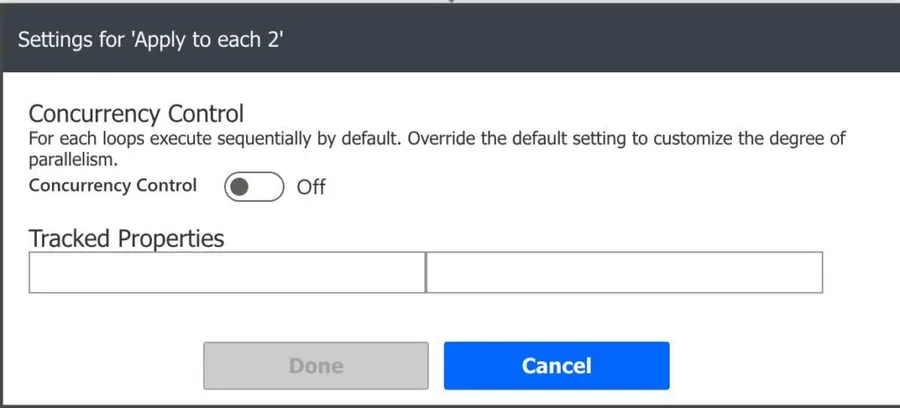
Since it’s disabled, we will only parse one element at the same time. To activate more, toggle the “Concurrency Control,” and you’ll see the following:
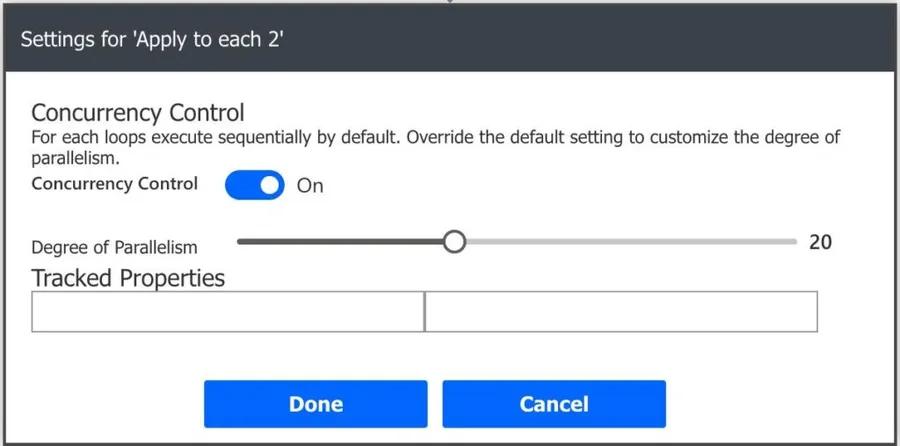
As you can see, the default value is 20, so change it to a value that makes sense for your Flow. It’s pretty simple and will make a world of difference in the time your Flow runs.
When not to use it?
Like everything, this is not a silver bullet that solves all problems. Before you enable it, don’t forget that you’ll have multiple instances running at the same time, so you should be careful if the order of the actions is essential. For example, you fetch an ordered list of people you want to insert in a text file. If you don’t enable parallelization, you’re sure to keep the order when you write to the file. But if you allow parallelization, you can’t control the order since Flow will register as soon as it's ready. Furthermore, it's impossible to know who writes to the file from all the instances running in parallel.
Another thing that you should keep in mind is the destination of the data. Databases are usually safe and prepared to handle concurrency, so you’re sure that, even if you have multiple instances running trying to access a database, it will cope with it. But other connectors are not lite this, and you may experience random errors when the destination of the data can’t cope with all the requests simultaneously.
I recommend that you test your Flow with more instances than you need. For example, if 20 is enough, set the value to 50 and see how it copes.
Trigger Flows
There are trigger Flows that have “Concurrency Controls,” but the concept is different here. Let’s check the Office 365 “When a new email arrives” trigger.
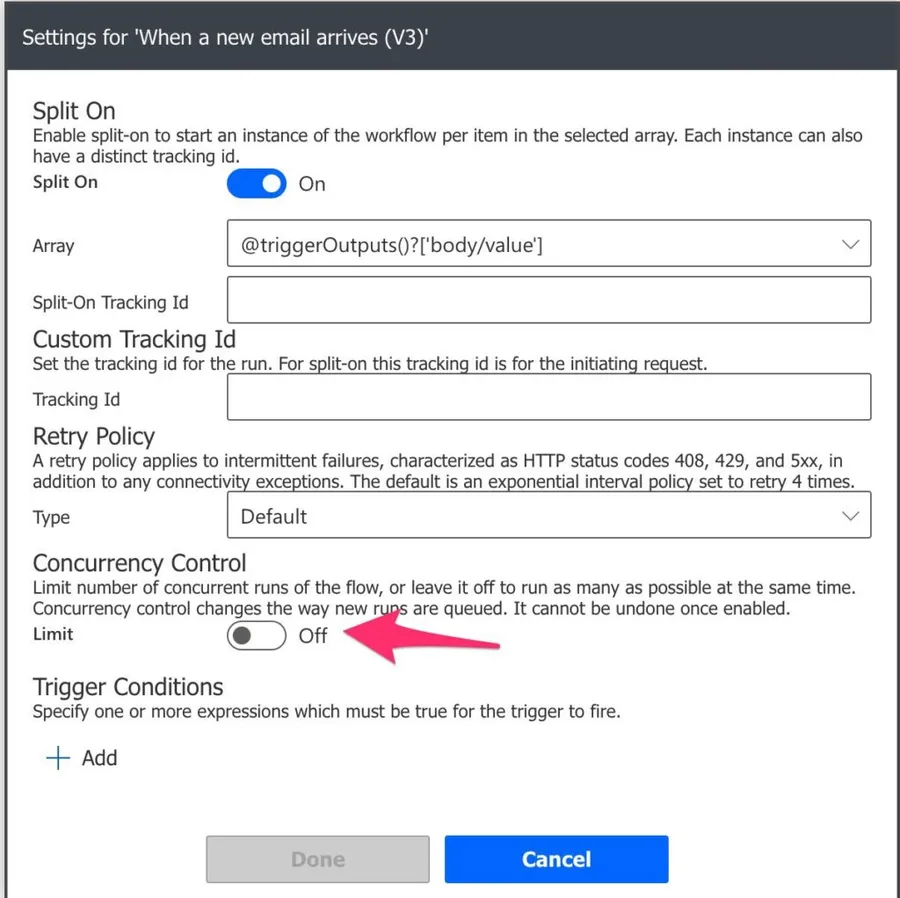
Here we’ll limit how many instances of the Flow can run at the same time. The default value is to have it disabled, so you can have as many instances as you want (depending on your license, of course) running simultaneously of the whole Flow. But if you toggle it, you’ll limit the number of Flows that can run simultaneously.
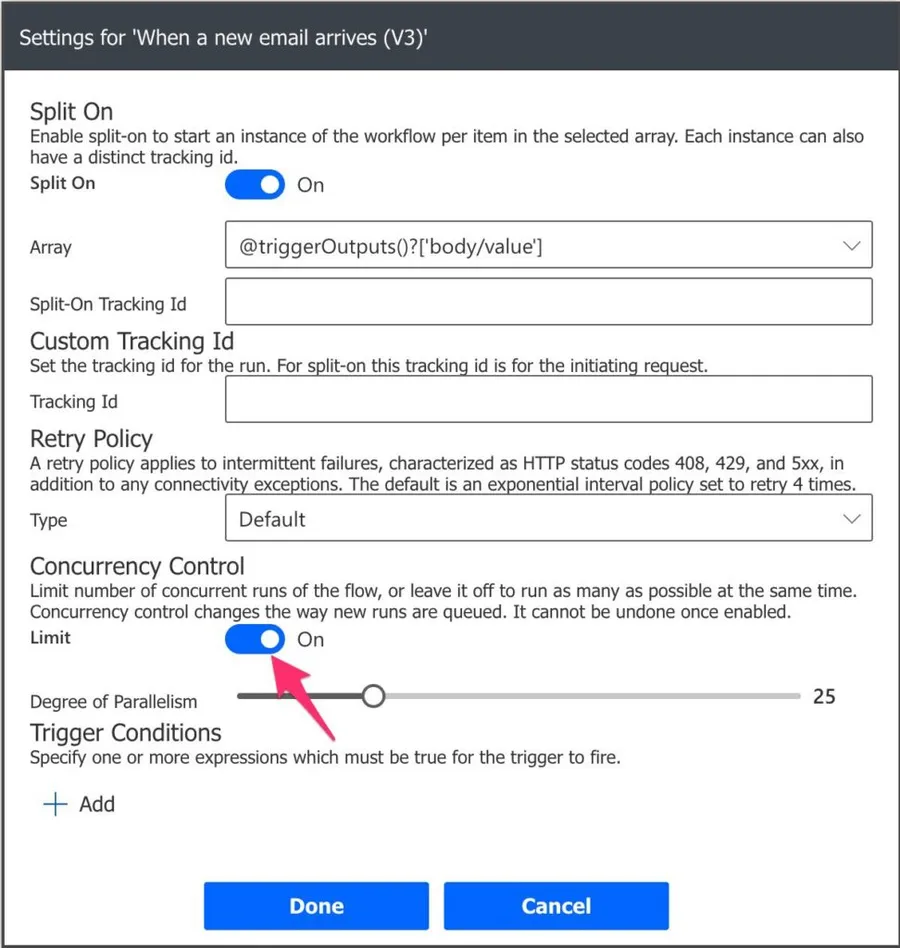
As you can see above, the default number is 25, but you can up to 100. I would strongly advise limiting the number of Flows that you can have running. It’s all about control, and if you have hundreds of Flows pending to end, you may have a problem that will only escalate if more Flows start running. Also, data can begin becoming corrupted if the Flows depend on the data to perform actions since the data is changed by its previous run.
So set a top limit that is comfortable, and if it goes above that, that deals with the errors.
Final thoughts
As you can see, there’s a lot of added value in having Flows run in parallel. Activating the “concurrency control” on both the triggers and the actions will provide you with faster Flows and more control on the number of parallel Flows as long as you’re sure of the consequences.
I would strongly advise you to check your Flows and see the ones that you can enable this. With a toggle, you can have speed without many drawbacks, so give it a go.
Photo by Jason Yuen on Unsplash



Hi I have question if you could help in following scenario: there are 10 concurrent power automate flows and each instance could last 1-10 sec I want to update a flag after all of the instances execution are completed. what is most elegant way to do it ? thank you