Today a brand new template that will get the HTML tag value from a piece of text. It’s part of a big project that I’m working on publishing here, and it will be ready soon.
I want to release this template as fast as possible to use it in case you.
Find HTML tag value
This template will enable you to get the value inside an HTML tag. More details about it are here.
So let’s check how to do this.
The assumptions
First, there are some things that we need to take into consideration:
- We’ll consider as a tag everything that is inside a
< >. You can put anything inside that I’ll not validate. - We won’t need a closing tag. For example, we will remove the start tag and return the correct values if we have the template.
- We don’t need the end tag to be
</...>. I will find the last occurrence of “<“ so anything after that will be ignored. - I won’t parse anything inside the tag. For example, if we have,
<a><strong>test</strong></a>we will return.<strong>test</strong>
Finally, the Flow will always return something. The return parameters are as follows:
- The value inside the tag
- The error in case something bad happens.
With this setup, you can call this Flow, with a “Run a Child Flow” action, for example, and deal with the errors if they occur.
The Template
We start with the trigger that is a “Manually trigger a Flow.”
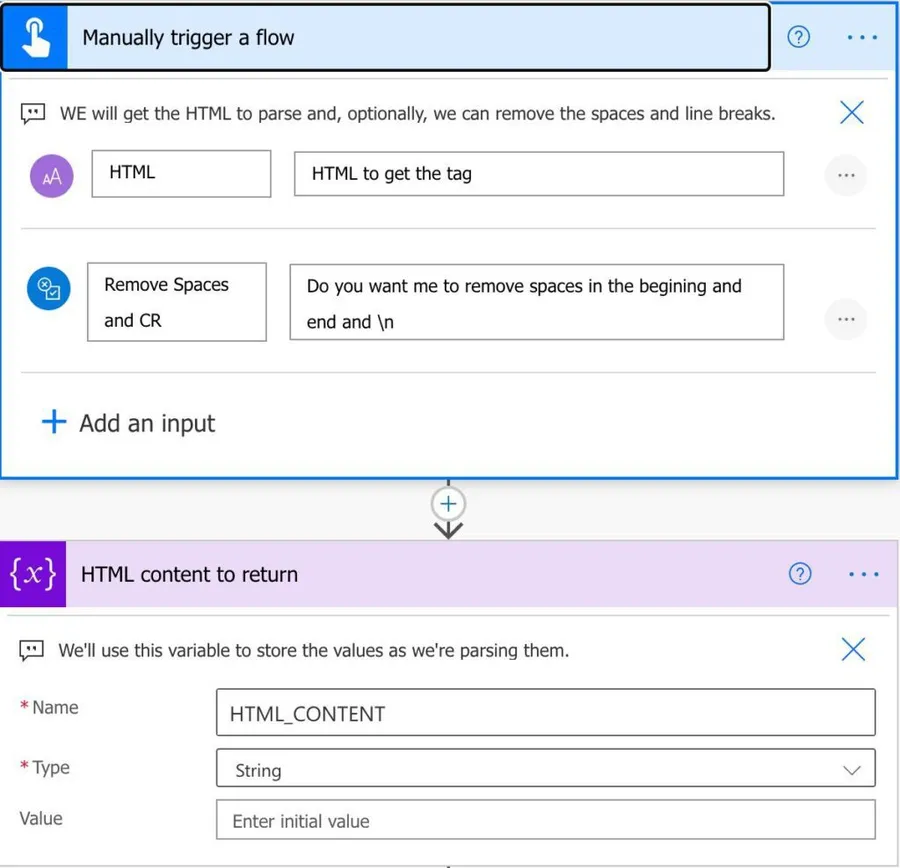
We have two parameters:
- The HTML to parse.
- Optionally if we want to remove the spaces and line breaks from their result, the default value is “false,” so we will only clean data if you want to.
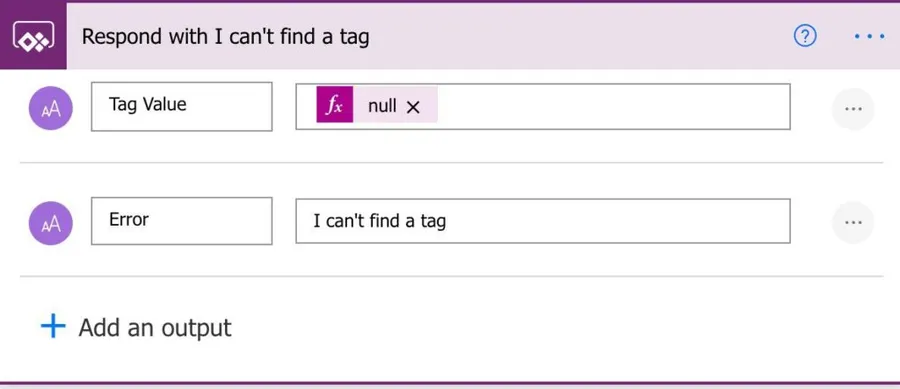
After that, we need to check if we have a start tag. If not, then we don’t have anything to parse.

If we don’t, then we will respond with an error and stop the Flow.
Clean the value
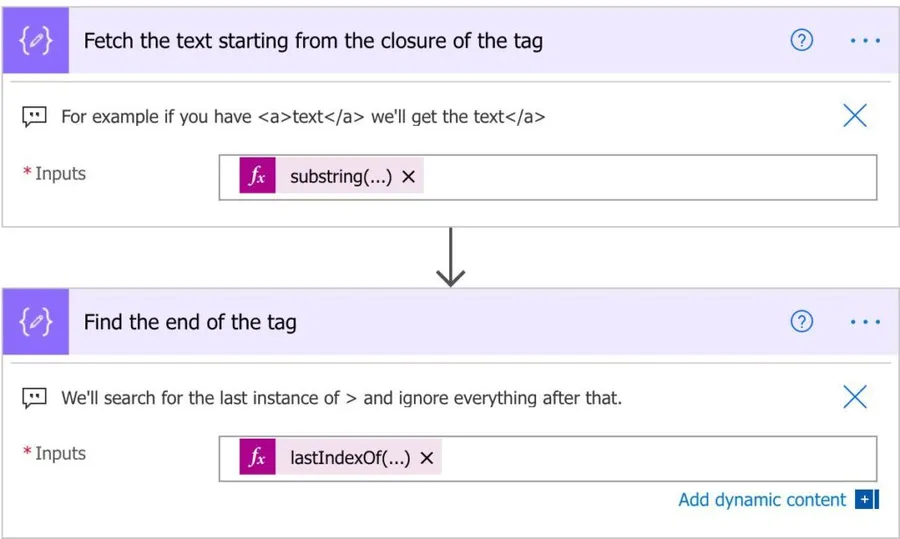
Now that we know that we have a tag, let’s fetch its position. To do that, we’ll use the following formula:
substring(triggerBody()['text'],add(indexOf(triggerBody()['text'],'>'),1))
First, let’s break it down into pieces:
- We find the first index of “>.” with the indexOf function.
- We add one since we want to remove that characters using the add function
- We do a substring starting on the value found until the end of the string using the substring function
For example:
<test>this is what we want</test>
In the first step, we find that the element is at index 5. We add another so that we get index 6. After that, we do a substring from index 6 until the end of the string, so we get:
this is what we want</test>
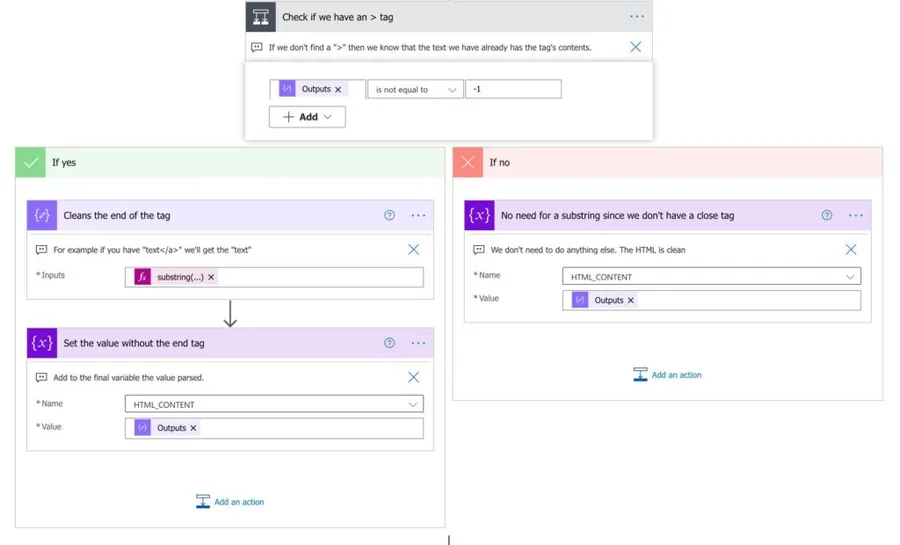
After that, we’ll find the end of the tag to clean the rest of the string. To do that, we’ll use the following formula:
lastIndexOf(outputs('Fetch_the_text_starting_from_the_closure_of_the_tag'),'<')
The lastIndexOf function can return one of two values:
- “-1” if it can’t find the string
- The index of the string.
Suppose we don’t, then there’s nothing else that we need to do. So the remaining string is what we want to get. But if we do, we need to do an additional operation to remove it to get only what’s inside the tag. To do that, we use the following formula:
substring(outputs('Fetch_the_text_starting_from_the_closure_of_the_tag'),0,lastIndexOf(outputs('Fetch_the_text_starting_from_the_closure_of_the_tag'),'<'))
The concept is the same as before, with the difference that we’ll always start with position zero, and we’ll find where we’ll want to stop and keep the text. To do that, we’ll use the lastIndexOf function again.
Clean spaces and line breaks
Finally, we can clean the spaces and line breaks if necessary. We will check if the parameter in the trigger is too true and deal with those if we need to:
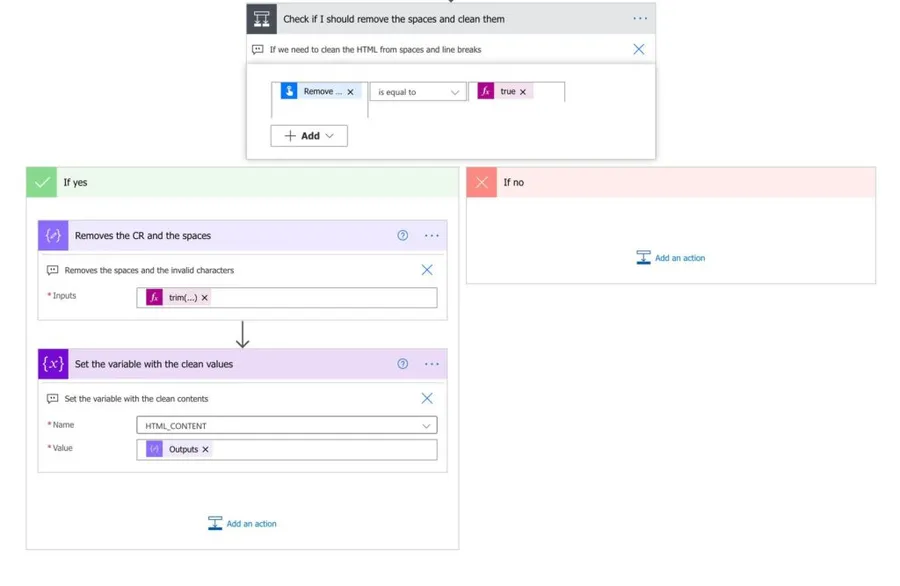
The formula is quite simple:
trim(replace(variables('HTML_CONTENT'),'\n',''))
We’ll use the trim function to clean spaces and the replace function to clean the line breaks.
Return and errors
As mentioned before, we’ll always return something, even if it’s an error. We do it with the “Respond to a PowerApp or flow” action.
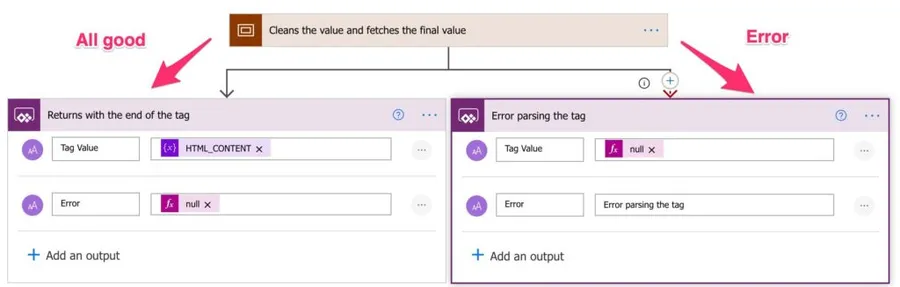
As you can see above, if all was parsed correctly, we’ll return the error as null and the “Tag Value” as the value inside the variable. Otherwise, we’ll return an error message so that you can deal with the error.
Final thoughts
The Flow is not as complex as one may think, but there are still some things to be careful of. It’s important to be aware of the assumptions and what to expect.
Please get in touch with pieces of HTML that are not being parsed correctly by the template. It helps me keep things better and keep on providing quality content to everyone.
Photo by Laurentiu Iordache on Unsplash



The template download link is about another article of yours and not related to this article at hand.
Good catch! You're absolutely right and all is fixed. Sorry about that!