
When parsing arrays, our first reaction is to add an "Apply to each" action to fetch elements. It makes sense, but how about when we know that there's only one element. It becomes cumbersome to have everything inside the Apply to Each, and it would be a lot simpler if we could get the unique value. So today, we'll see how to parse an array more efficiently without an "Apply to each".
The problem
So let's look at a previous template where we get the earlier versions of the items in the SharePoint list.
How to get previous versions of data in a list
There are times when it's helpful to fetch the previous versions, so this template will help you do that. In addition, I wrote an article explaining all the processes so, if you have any questions, you can check it here.
We're filtering an array with items in the template, but the "Filter Array" action will always return an array. Furthermore, we know that the version we're filtering exists in this case, so we're sure it's returning one element. Finally, the "Apply to each" will always parse once, so we can simplify it by fetching the first element and using it from thereon, without putting all actions inside it.
Another example is when we have an array of elements and know that we want one in a position. To do it:
- Define a variable to store the value
- Define a variable for the index
- "Apply to each" on all elements and increment the index
- If the index is the same as the number, we want to save the value to the variable.
It's pretty ugly and cumbersome. Also, if the array is enormous, our Flow would take a lot of time to run when we only want one element, and we know what element it is.
The solution
So let's see potential solutions to parse an array more efficiently.
There's only one value.
Let's think about a list of employees. We want our Flow to calculate average age and average salary from all values.
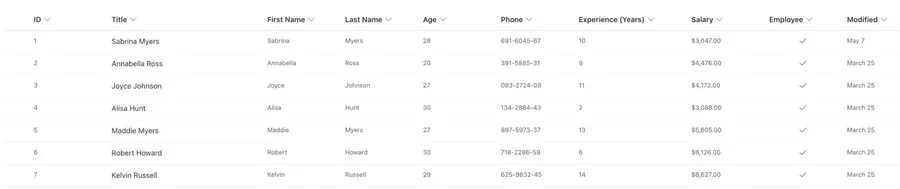
We get the complete list of values, and we start to calculate things. At the end of the calculation, we want to get the person with the highest salary that we stored in the analysis. You can either store the ID or the pay. It's the same thing for our purposes.
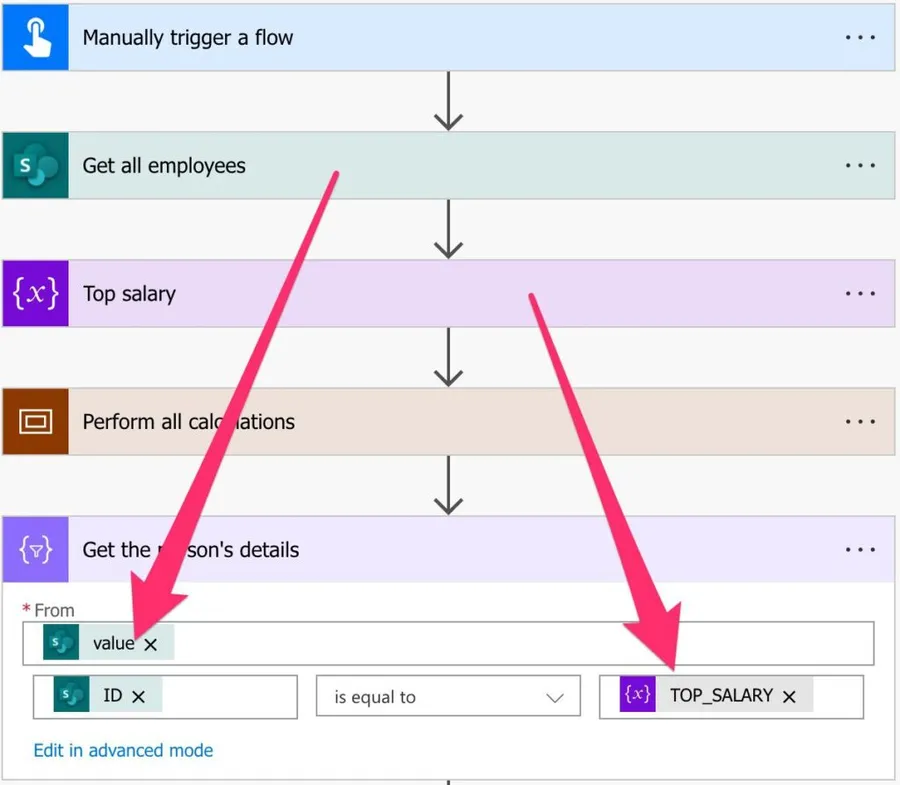
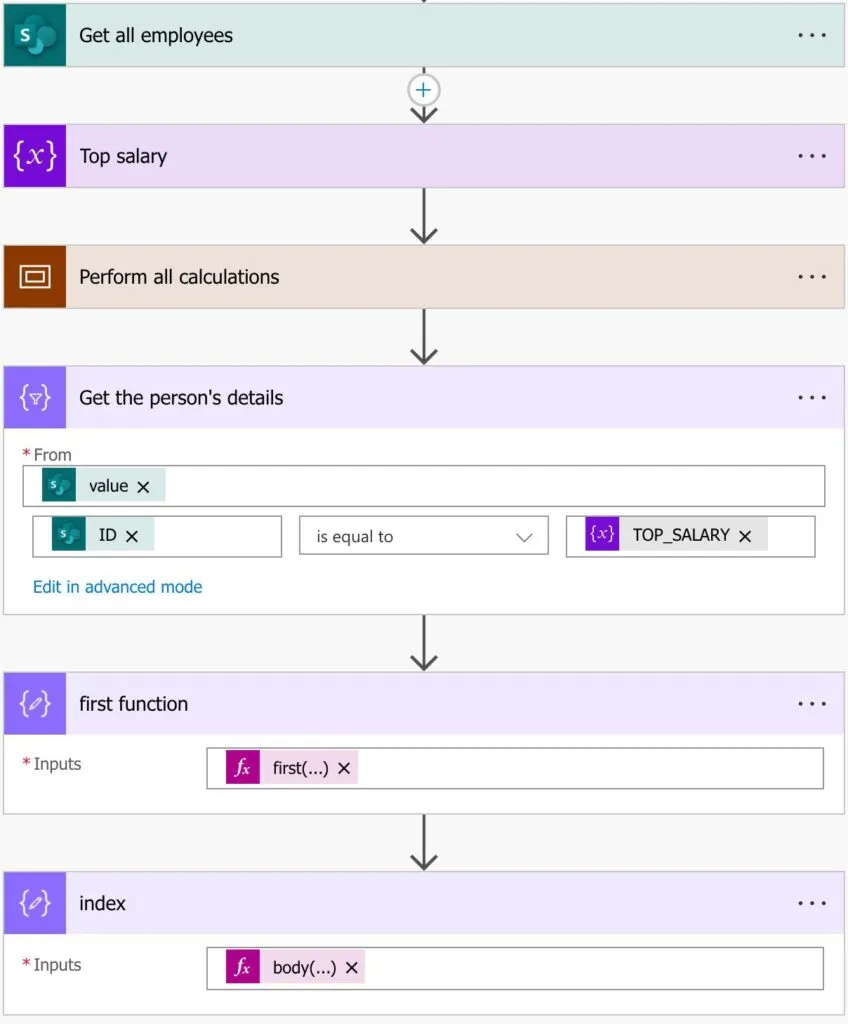
The Filter action will return another array, but we know for sure that we're only fetching one person, and that person exists. So an "Apply to each" is a lot slower and wasteful. So here we have two things that we can do:
- Use the first function
- Fetch the item by index
The first function expression is as follows:
first(body('Get_the_person''s_details'))
And the item by the index is as follows:
body('Get_the_person''s_details')[0]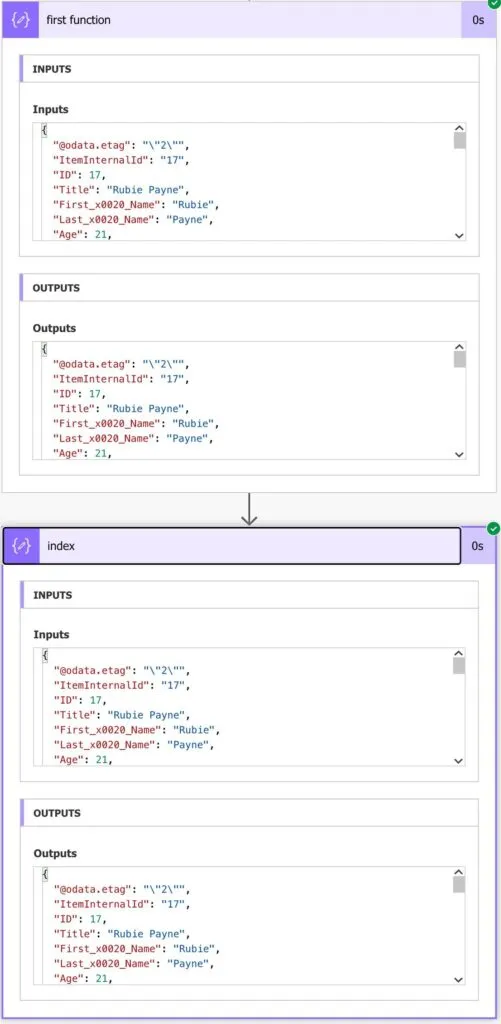
Here's the result of both:
We get the same effect, and the Flow is super fast to run.
So we know the item we want.
In the example above, we already did it when we did the following expression:
body('Get_the_person''s_details')[0]
The zero is the index of the element we want to fetch.
How can we make it so that we don't have an error? We can indicate Power Automate that we can "try" to access the value, but it's okay if it doesn't exist. To do that, we can add a simple question mark and indicate that the value is optional. Here's the new expression:
body('Get_the_person''s_details')?[0]
The Flow will return an empty value if the index doesn't exist instead of an error.
Advantages
Here are some benefits of this strategy.
Better performance
Since we're only fetching the data once, the Flow will run a lot faster. Imagine if, each time you need information, you need to go to SharePoint and fetch the data all over again. Even if your Flow doesn't need to run quickly, keep an eye on performance. If there are slow running Flows, you can have issues that you don't foresee, for example, when the "next" Flow starts running when the previous one didn't finish yet.
Much more readable
Since we're doing a lot of actions in only two actions, the Flow is a lot more readable. Readability is directly related to the speed to fix issues and avoid them if you're changing them. So never compromise readability.
Stable Flows
Since we're fetching information that we sure exist, the Flows will be a lot more stable. Also, since we're parsing information that Flow fetched at a point in time, it's much easier to avoid issues like overriding information. For example, let's imagine that you don't use this strategy. You calculate, and it takes a while. When you try to fetch the data again to proceed, the data has changed. You may be trying to access a record that doesn't exist anymore. With bringing the elements before, we have a stable snapshot in time that things are consistent. If we need to update after the data, it's okay since we get another snapshot.
Final thoughts
Although it's not always possible to use this strategy, you should know about it. Arrays are pretty standard when building a Flow, so it's essential to understand how parse an array more efficiently. Be conscious of your Flows and how they run, and try to make them run as fast as possible. Also, it's a lot cleaner to have a Flow with fewer actions, so keep this in mind.
Photo by Charlotte Coneybeer on Unsplash



No comments yet
Be the first to share your thoughts on this article!