
SharePoint is an excellent place to keep files and manage them. Most of the time, we can access the file directly and edit it, like an Excel file, for example, but today, we’re interested in the file as a blob of information. We want to get the file contents and then use them elsewhere in our automation, like sending it in an email, for example.
A few notes before we continue. There’s a “sister” action called “Get file content using path” that works differently. We'll see it in a bit, but this one requires an "Identifier," while the other requires you to provide the file's path.
Also, there are analogous functions for OneDrive For Business, like the “Get File Content” action and the “Get File Content using Path” action, in case you’re interested in using OneDrive instead of SharePoint.
Where to find the "Get File Content" action?
You can find it in “Standard”.
If you don’t see “SharePoint,” click to expand.
Pick “SharePoint”.

Pick the “Get file content” action.
Here’s what it looks like.

There are also advanced options that you can pick by pressing the “Show advanced options”.
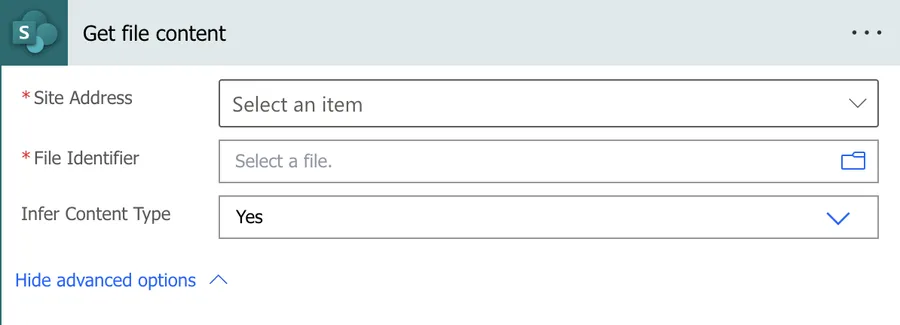
Now that we know how to find it let’s understand how to use it.
Usage
The usage is quite simple. There are two parameters:
- The SharePoint site where you have the file
- The file itself.
It’s important to note that you must pick the file from the UI and not provide its path. Check below on the “non-intuitive behaviors” for more details. Here’s what it looks like:
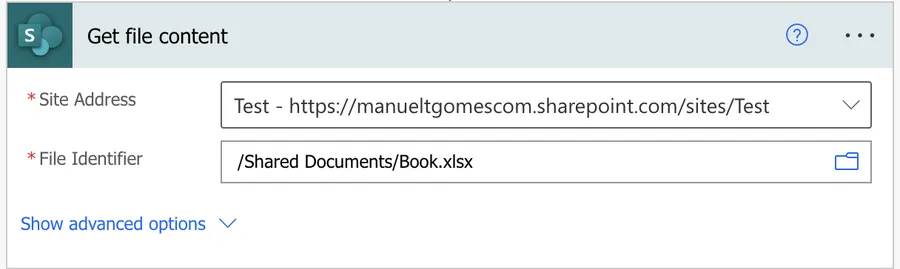
When we run it, we get the following:
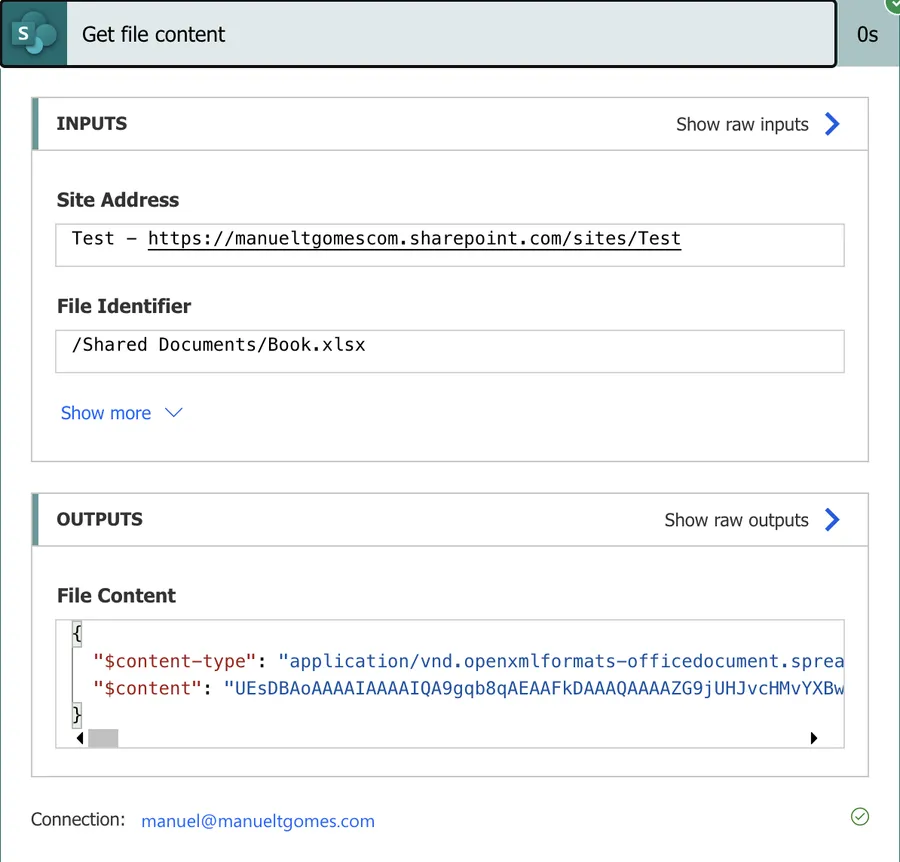
Notice that the data that we get looks “strange”. Since we’re getting an Excel file with an internal structure that is not readable by us, we’re getting its result in base64. If you don’t know what it is, don’t worry. In this case, consider it as “data” and provide it to the actions that require the information, and Power Automate will take care of the rest.
What about if we try to fetch the information from a text file like this?
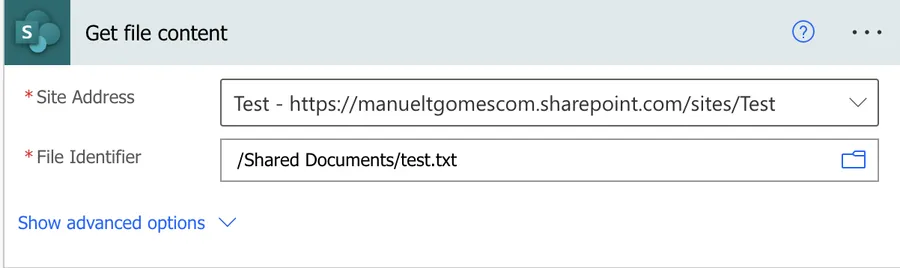
The “Get File Content” action will return the following.
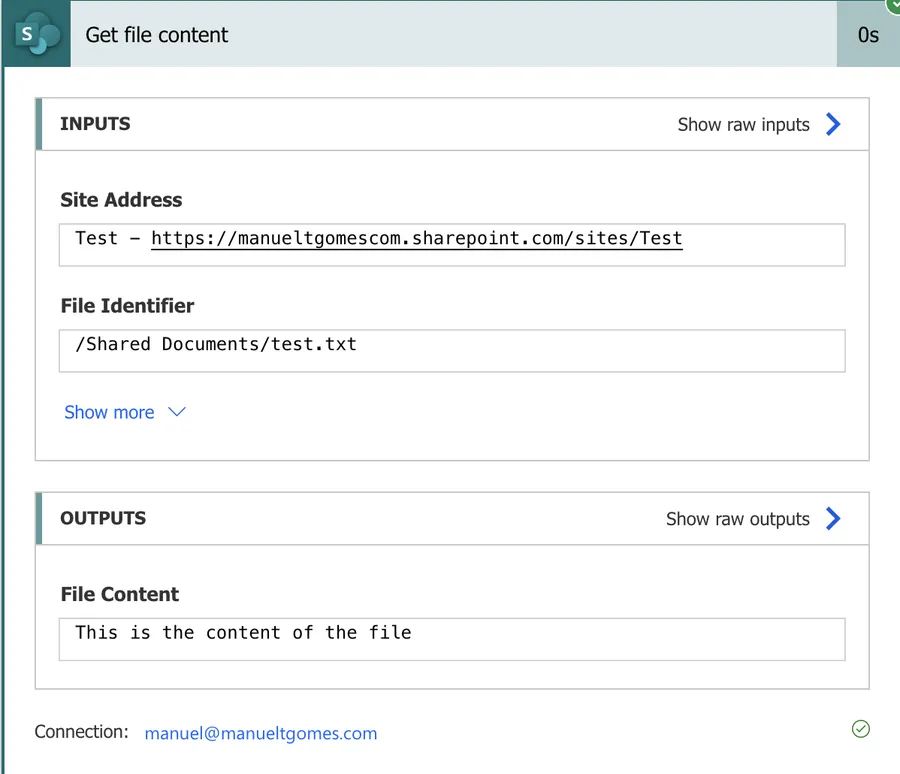
Since we’re getting a text file, we won’t get it as a base64 file, but we’ll get its contents. This works the same way with CSV files, where the information is stored in clear text that you can “read”. Again, this is a great way to get information in bulk from a file and parse it in subsequential actions.
Finally, look at the advanced properties, like the “Infer Content Type”. This tells Power Automate to look at the extension and try to understand the content type. For an Excel file, it’s something like this:
application/vnd.openxmlformats-officedocument.spreadsheetml.sheet
Applications need this information to know what to do with the files and how to open them, for example.
It’s super rare that you’ll need to worry about this, but I wanted to include an explanation of what it is in case you’re curious or facing a situation where you need it. If you do, please let me know in the comments so I can include it here for others to benefit.
Non-intuitive behaviors
Some people see the path in action and wrongly assume that they can provide it dynamically.
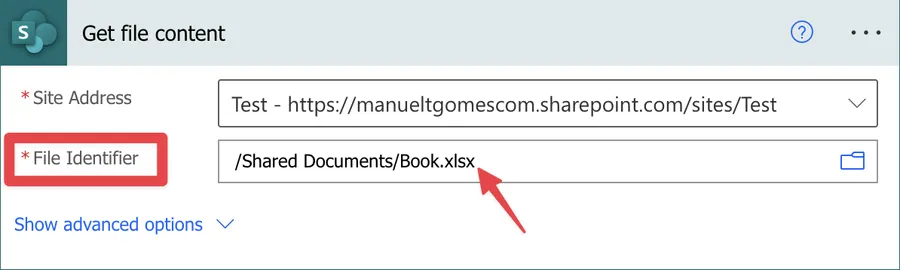
Notice that the action’s parameter is called “File Identifier” and not “File Path”. You can use the file identifier if you can get it from other actions, but it won’t work with the path.
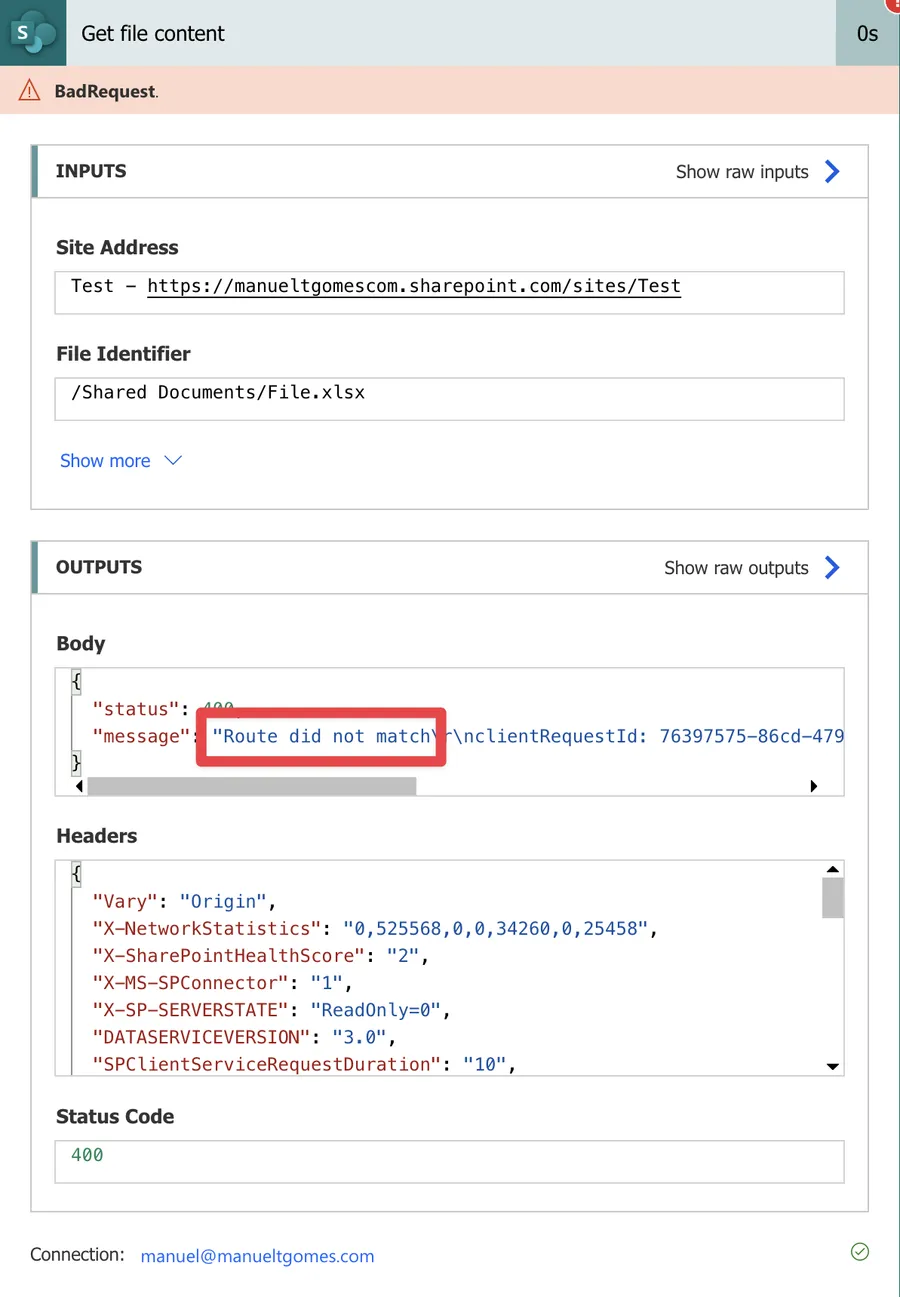
If you try to do it, you’ll get an error message like this:
Route did not match
clientRequestId: b86c99b3-8408-4b44-8912-edcf070bbcdd
serviceRequestId: faf84c19-2e41-4c8f-a822-d6592d850991
Here’s a quick way to test it. First, copy the value we got before to a “Compose” action.
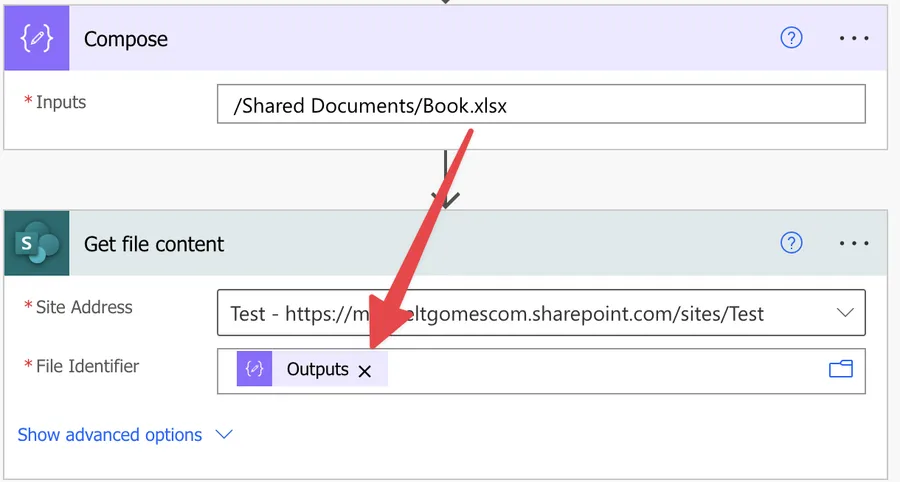
Here’s the result.
If you want to use the path dynamically, you need to use SharePoint’s “Get File Content using Path” action.
Limitations
I could not find a hard limitation for the size of the files, but I’m sure there’s one. Don’t try to parse large files because you can hit Power Automate’s throughput limitations.
If you have found a limitation we should be aware of, please comment, and I’ll include it in the article for everyone to benefit.
Recommendations
Here are some things to keep in mind.
Name it correctly
The name is super important in this case because we can pick the file from the UI and get the file’s Identifier from other actions in the Flow. Therefore, always build the name so others can understand your use without opening the action and checking the details.
Always add a comment.
Adding a comment will also help avoid mistakes. Indicate where the Identifier comes from, for example, how you get it. It’s essential to enable faster debugging when something goes wrong.
Always deal with errors.
Have your Flow fail graciously and notify someone that something failed. It’s horrible to have failing Flows in Power Automate since they may go unlooked-for a while or generate even worse errors. I have a template that you can use to help you make your Flow resistant to issues. You can check all details here.
Back to the Power Automate Action Reference.
Photo by Ali Shah Lakhani on Unsplash



Great intro to what the connector does! Any idea how to decode the content for xlsx file from this connector? I am trying to parse to json so I can extract the columns and data into SQL. I cannot use list rows in table excel online connector, since the excel files are located in on-prem sharepoint. Any help would be greatly appreciated !
How do you specify the file path when using the "Get File Content" action?
Great explanation Manuel. Appreciate your efforts. I am looking at getting file content, identify if the content has specific words and then move the file to specific folder based on the key words in the content.
We encountered Internal Server Errors when trying to read .json files where the root structure is an array instead of an object. Power Automate struggles to infer these documents as JSON. To remedy, rename the extension to .txt so the content type is inferred as text/plain. The Parse JSON action will then works correctl.
I'm trying to include the content of a Site Page (*.aspx file) in the email body. I can grab the properties of the file but the email is blank. Wondering if I need to change the Infer Content Type to something other than Yes.
Just a quick clarification for those using the online interface (haven't tested in desktop). You CAN dynamically identify the file from SharePoint, but you need to use the {Identifier} value from the File Properties (this works in both classic and modern interfaces). For example, if you are using the "When an item or a file is modified" trigger, set the Identifier field to: triggerBody()?['{Identifier}'] This property will show up in the dynamic list, so you don't need to use the insert expression if you don't want to. Do not include the file path, library name, etc. or it will fail (also do not use the uriComponent function.) Finally, the file MUST have content. If you're using an empty .txt file for testing, you'll get an error stating that the content is null.