 by
by The “xpath function” is not the first function that comes to mind in Power Automate, and it’s not the most obvious; I’ll give you that, but it can be super powerful and useful if you understand how it works. The function will help us parse XML files to find information, get blocks of nodes, and even get analytics on the file, like the number of nodes. Again, it’s not the most straightforward, but I’ll do my best to explain how to take advantage of it and how it works.
Let’s start where you can find it.
Where to find the “xpath” function?
You can find the function in every action where a formula is supported. For example, let’s look at a “Compose” action:
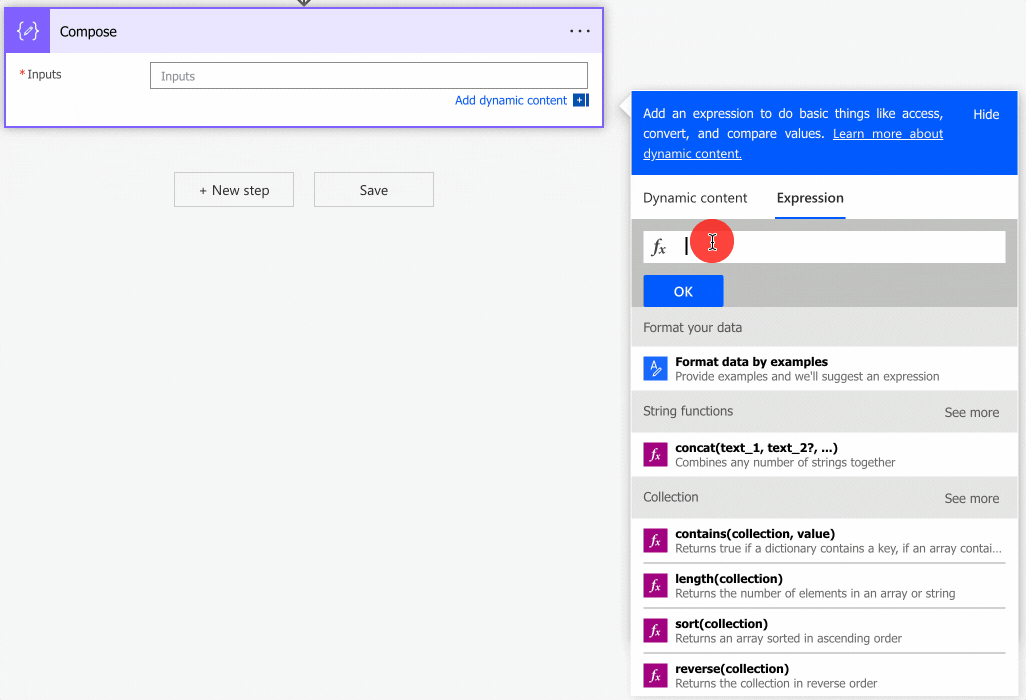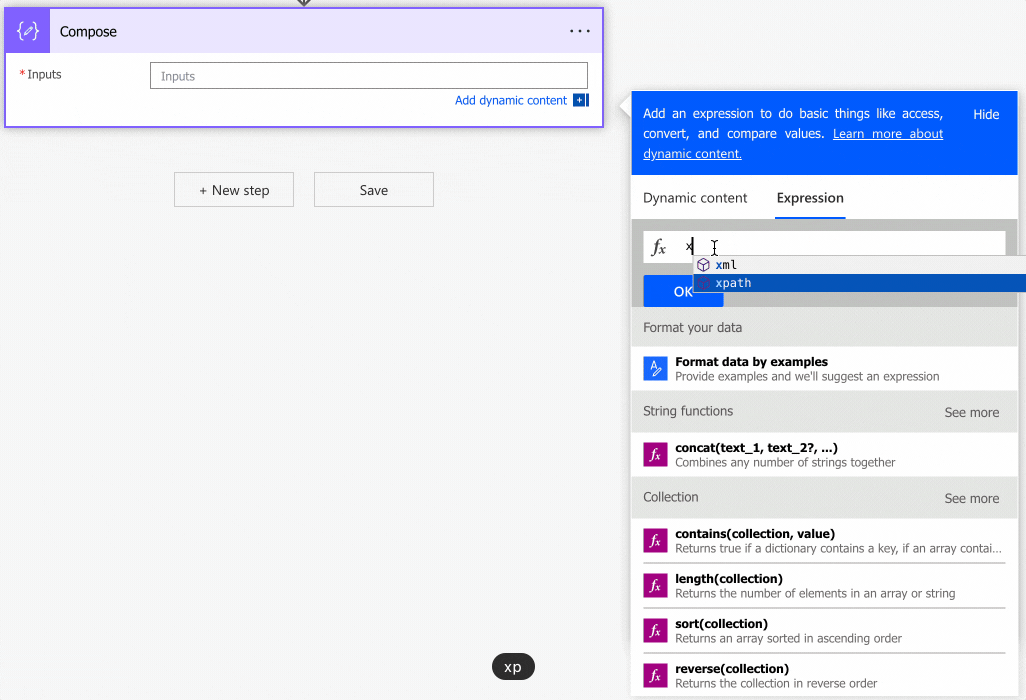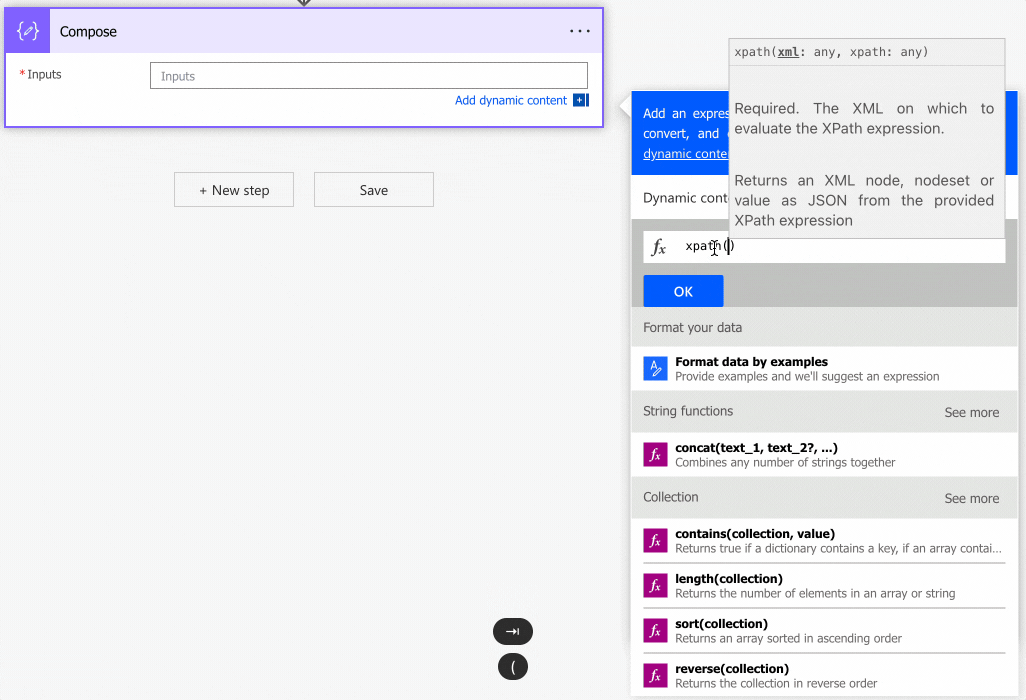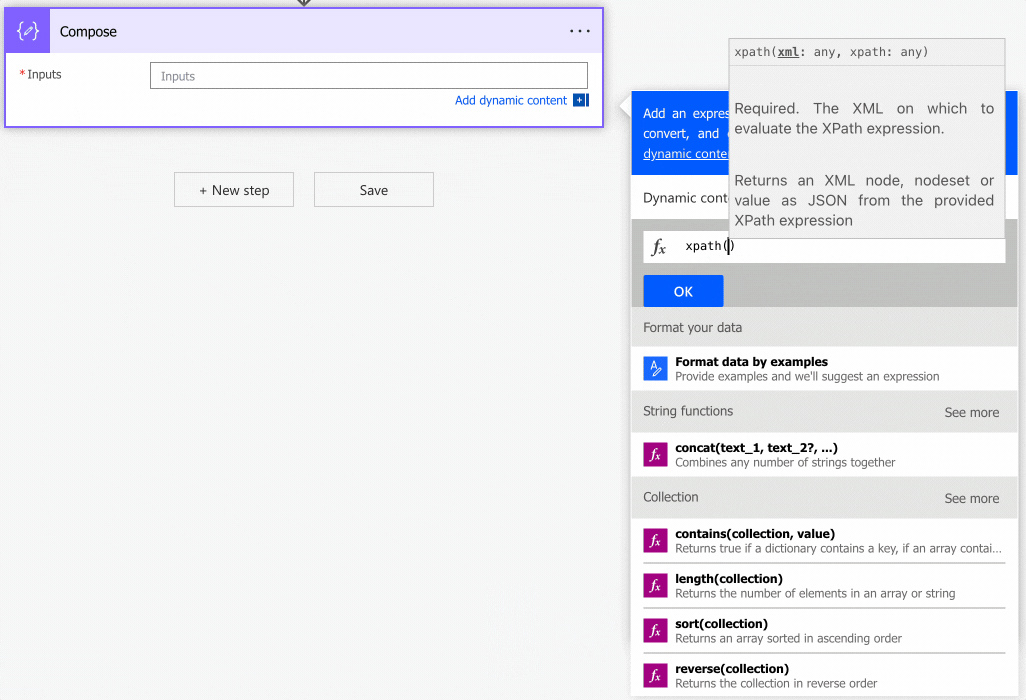
As you can see, we can auto-complete by using the “tab” key. Let’s look at how to use it.
Usage
It follows a simple pattern.
- XML document to look for data.
- The expression
This function requires that the first parameter is an XML Document, not a string. This is something that most people get wrong, so please take this into consideration. If you get an error, please refer to the “Common Mistakes” section below for potential solutions.
Test XML
I’ll perform actions on the following sample XML document to keep the examples short and not include the full XML definition. You can find a copy of this file in Microsoft’s Official Documentation.
<catalog>
<book id="bk101">
<author>Gambardella, Matthew</author>
<title>XML Developer's Guide</title>
<genre>Computer</genre>
<price>44.95</price>
<publish_date>2000-10-01</publish_date>
<description>An in-depth look at creating applications
with XML.</description>
</book>
......
<book id="bk112">
<author>Galos, Mike</author>
<title>Visual Studio 7: A Comprehensive Guide</title>
<genre>Computer</genre>
<price>49.95</price>
<publish_date>2001-04-16</publish_date>
<description>Microsoft Visual Studio 7 is explored in depth,
looking at how Visual Basic, Visual C++, C#, and ASP+ are
integrated into a comprehensive development
environment.</description>
</book>
</catalog>
Here’s how we’re using it:

As we mentioned before, the XML provided to the function cannot be a string, so we need first to convert it. Another important thing to understand is that the “xpath function” won’t return a string, but we’ll explore this in the next example.
Get all the elements
Let’s start with something simple. Let’s get all the “ book“ elements in the XML document. To do that, we use the names in the XML separated by forward slashes like this.
xpath(outputs('Convert_to_XML'),'/catalog/book')
The first slash means that we want to start at the beginning of the XML, and the first node needs to be called “catalog” that has a sub-element called “book”. Finally, the “book” has other elements, one of them called “author”. If any of the elements in the path are not found, then the function won’t return a value. For some people this is counter intuitive because they would expect that Power Automate would return an error, but no. Power Automate will return an empty array , like this:
If you don’t know the full path of the elements, that’s not a problem. We can define the one that we want like this:
xpath(outputs('Convert_to_XML'),'//book')
The above will search the whole XML tree and find all tags called “author,” regardless of where they are.
When you run the Flow, you’ll get the following:
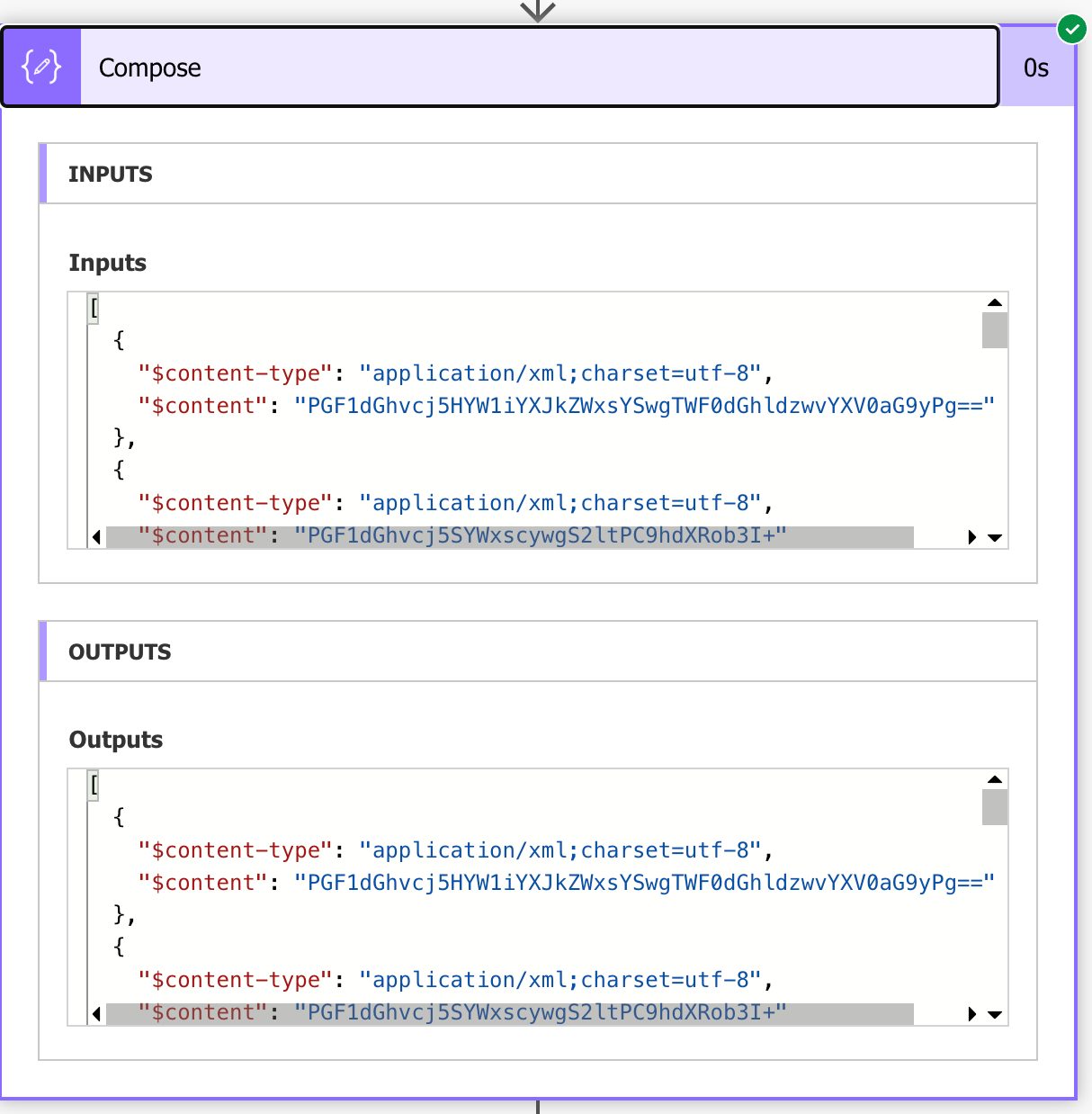
This looks scary, but let’s understand the whole process. As we mentioned before, the “xpath function” will search for all elements that are “book” so it will return an array of elements, as demonstrated above by the square brackets. The “content-type” indicates that we have an XML, and the “content” is the corresponding content in base64.
In Consumption and Standard logic apps, all function expressions use the .NET XPath library. XPath expressions are compatible with the underlying .NET library and support only the expression that the underlying .NET library supports.
This means that the technology that supports the “xpath” function works like this, so we get the values as base64.
We can then get the content by using the XML again in each array item. For example, let’s build an HTML table with the result as follows:
In the value, we have the following formula:
xml(item())
Here’s the result:
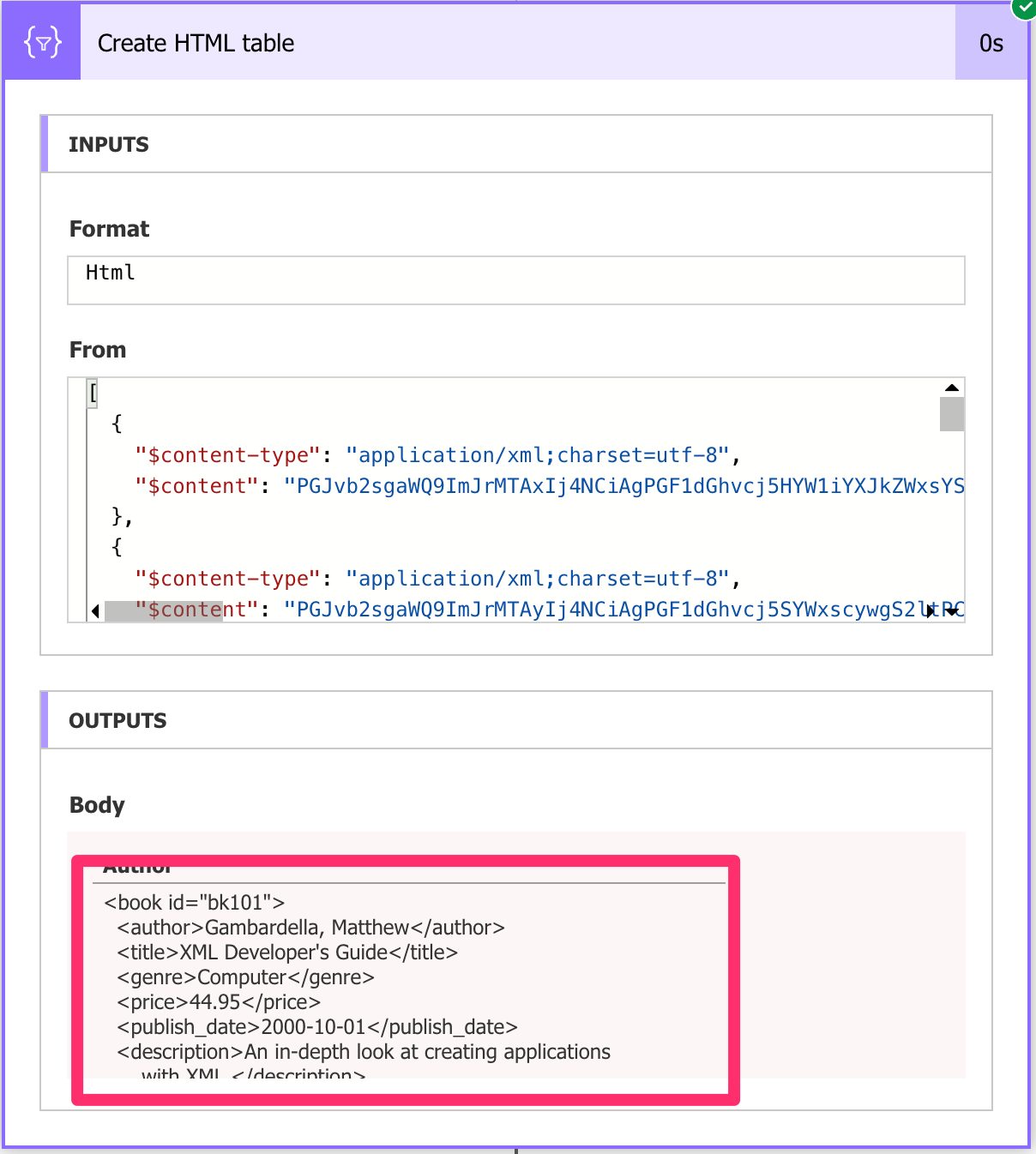
We get the whole structure under “book,” and that’s not very useful, but I wanted to show you how to get the value from the result in a format that we can read. In your Flows you’ll do additional parsing (see below how to get each string of the element easily) to display or parse the results.
Let’s look at other ways to get the data.
Get the author for the first book
Now let’s get the value from the first author in the list. To do that, we need to indicate that we want the first book and then get the author’s information, like this:
xpath(outputs('Convert_to_XML'),'string(//book[1]/author)')
We’ll get the following result.
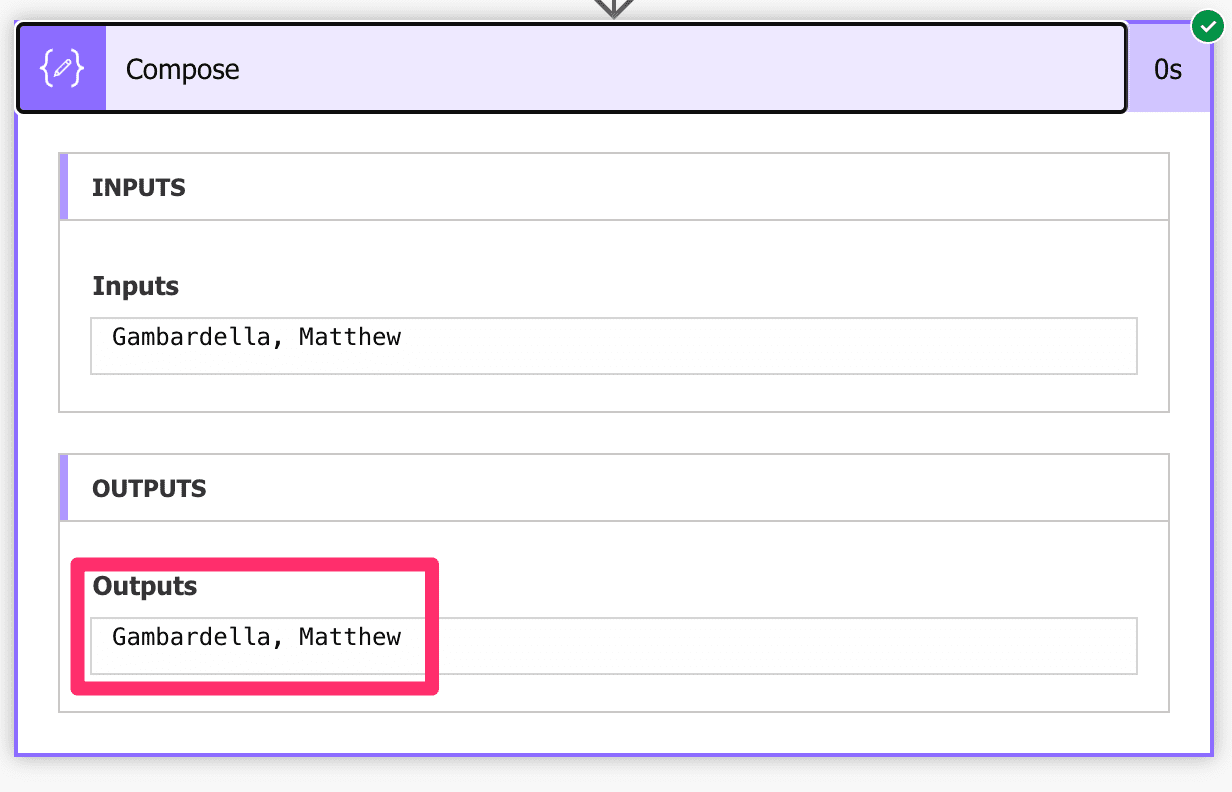
Let’s unpack the formula from the inside out:
//book[1]/author– we indicate to the “xpath function” that we want the first book by using the [1] and then say we want the “author” element inside the first “book” element. Notice that we used 1 and not 0 like we normally do in Power Automate.- String – this will indicate that we don’t want to get the full element like “<author>Gambardella, Matthew</author>” but only the string value inside. Notice as well that we’re doing this inside the quotes because this is not a Power Automate function, but something we provide to the engine that takes care of the XML parsing.
- The rest of the formula is as before. We provide the converted XML to the “xpath function” and get the result.
I like to include the index so that we know what element we’re fetching, but if you want the first one, you can remove the [1] like this:
xpath(outputs('Convert_to_XML'),'string(//book/author)')
You’ll get the same result because of the “string” function.
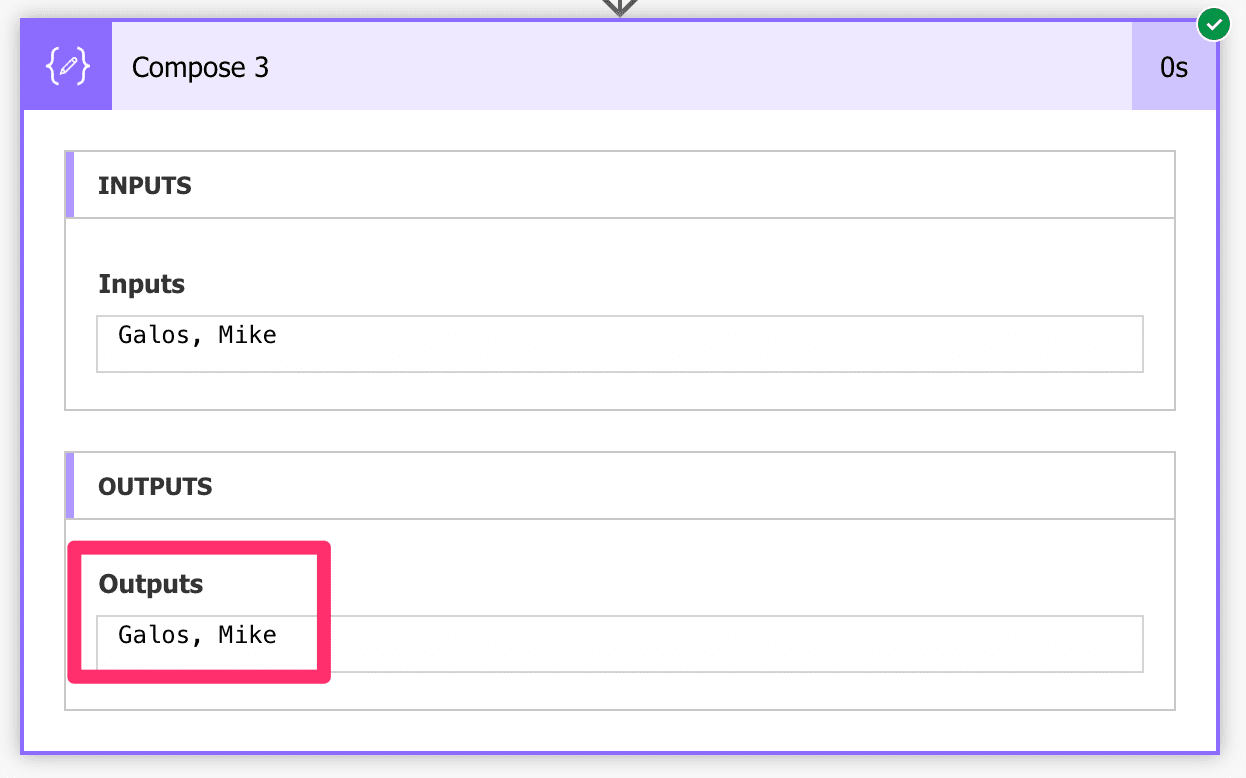
Get the author for the last book
Let’s say that we want the last author of the array, but we don’t know how many there are, so we don’t know what number we can put there safely. Fortunately, there’s a nice way to indicate that we want the last by using the “last” function inside the expression.
xpath(outputs('Convert_to_XML'), 'string(//book[last()]/author)')
Notice again that we’re , not using Power Automate functions and putting everything inside the single quotes. Here’s what we’ll get:
Get only values
In previous examples we’ve always searched for XML elements but what if we want to get a list of the values in an element? For example, get a list of all authors? Here’s how to do it:
xpath(outputs('Convert_to_XML'),'//catalog/book/author/text()')
We’ve added the “text()” at the end to indicate that we don’t want the “xpath” function to return another XML document but an array of text values. Think of this as using the “string” but for all elements. Here’s the result:
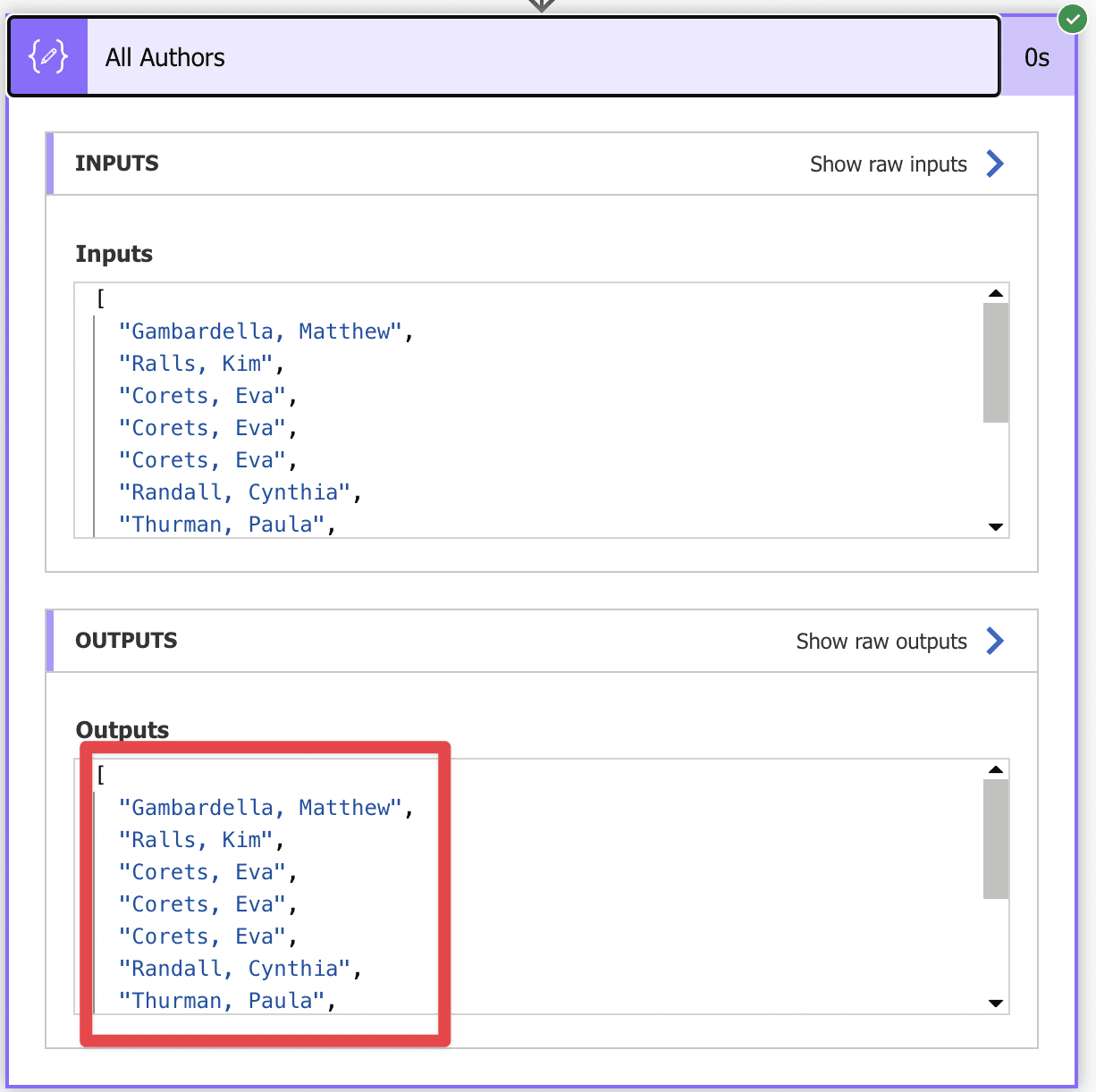
Notice that we have an array of strings, so further conversion is necessary.
Filter based on an attribute of the element
Let’s say that we know an attribute of the book, like the one called “id,” and you want to search for the value “bk102”. One way could be to search all elements of the XML, but that could take time and effort. Microsoft’s documentation shows us that we need to use the following syntax:
//book[@id = 'bk102']
The @ sign will indicate that we’re looking at an attribute and that the attribute needs to be equal to something, or in our case, “bk102”. But when we build the expression, we get an error.

What gives?
The problem is the single quotes. Power Automate requires that the parameters of the functions, like the “xpath” function, are encompassed in single quotes; since we’re providing a parameter that also requires single quotes, the expression validator of Power Automate sends warning signs that the expression is incorrect. I have another alternative solution to this problem below, but you can quickly solve this by encompassing the inner expression with another set of single quotes like this:
xpath(outputs('Convert_to_XML'), '//book[@id = ''bk102'']')
This way, Flow will return the second parameter as a whole to the Power Automate’s engine that parses the “xpath function,” and the engine will then have a valid parameter to process.
Find values based on criteria.
Before, we checked the elements based on the attribute, but what about if you want to check based on the element’s value? For example, check all elements that are “book” with another sub-element called “genre,” and its value is “Computer”.
Here’s how to do it.
xpath(outputs('Convert_to_XML'), '//book[genre=''Computer'']')
It follows the same strategy as before when we searched by using an index or a function (for example, the “last()” function). Now we’re providing a comparison, so the engine will look at all items that are books, and, for those with a “gender” element, it will check if it satisfies our criteria.
We can go even bit further by using comparisons other than equals like this:
xpath(outputs('Convert_to_XML'), '//book[price>10]')
With this, we’ll get all books with an element called “price”, which is above 10.
Check how many elements.
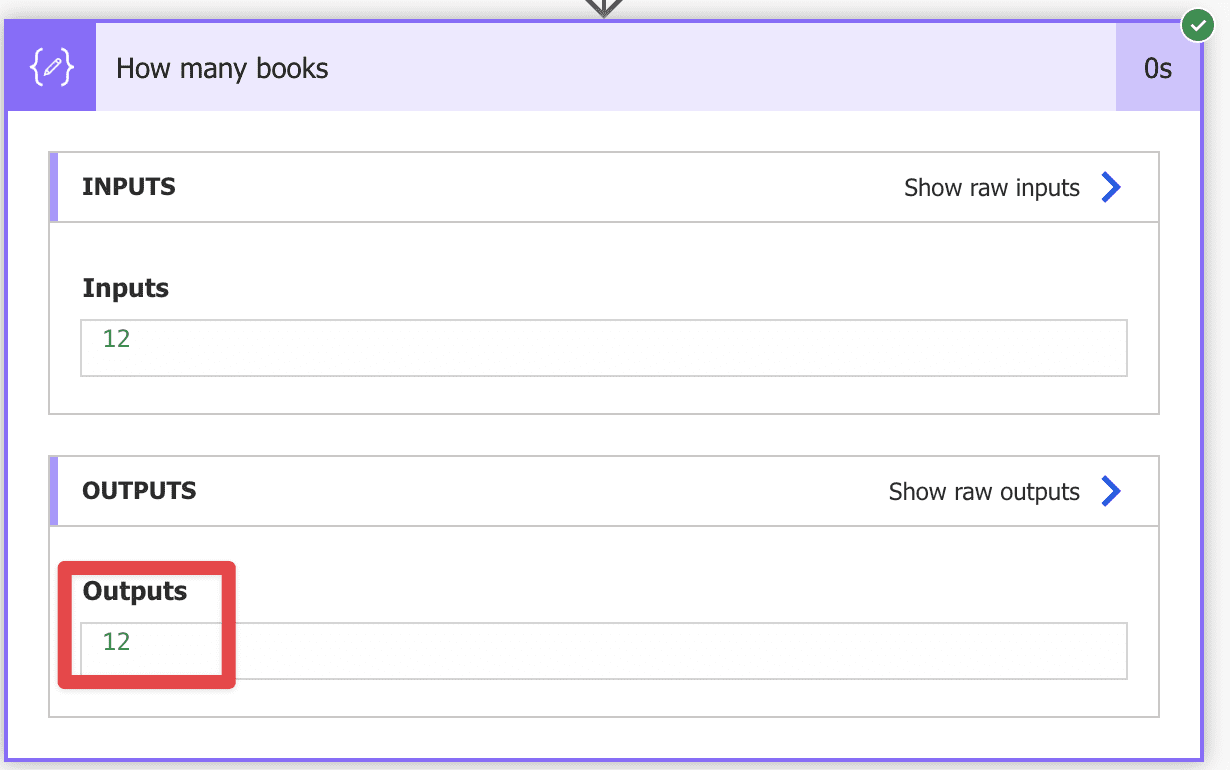
Sometimes we’re not interested in a specific element but how many there are. Like before, we could iterate and count them, but that’s too cumbersome and slow, so using the previous example, let’s check how many books there are in the XML.
xpath(outputs('Convert_to_XML'), 'count(//book)')
We use it similarly to the “string” function by providing the element we want to count. Here’s the result for the test file:
Namespaces
Finally, we’ll explore namespaces. There’s a good explanation here on why they exist, but you can spot them in XML like this:
<h:table xmlns:h="http://www.w3.org/TR/html4/">
<h:tr>
<h:td>Apples</h:td>
<h:td>Bananas</h:td>
</h:tr>
</h:table>
Notice that the XML contains a prefix for each of the elements. When we search, we need to tell the parser that we want to ignore the namespace; otherwise, the elements won’t be found. Let’s put this into practice. Let’s say that we change our test XML to contain the namespaces like this:
<h:catalog xmlns:h="http://www.w3.org/TR/html4/">
<h:book id="bk101">
<h:author>Gambardella, Matthew</h:author>
<h:title>XML Developer's Guide</h:title>
<h:genre>Computer</h:genre>
<h:price>44.95</h:price>
<h:publish_date>2000-10-01</h:publish_date>
<h:description>An in-depth look at creating applications
with XML.</h:description>
</h:book>
......
<h:book id="bk112">
<h:author>Galos, Mike</h:author>
<h:title>Visual Studio 7: A Comprehensive Guide</h:title>
<h:genre>Computer</h:genre>
<h:price>49.95</h:price>
<h:publish_date>2001-04-16</h:publish_date>
<h:description>Microsoft Visual Studio 7 is explored in depth,
looking at how Visual Basic, Visual C++, C#, and ASP+ are
integrated into a comprehensive development
environment.</h:description>
</h:book>
</h:catalog>
As a refresher, here’s how we get the first element:
xpath(outputs('Convert_to_XML'),'string(//book/author)')
Since we have a fixed name above for “book” and “author” we can define it statically, but if there’s a namespace, we need to use the following syntax to do an additional search for the name of the element:
*[local-name()="book"]
This will use the “local-name” function to check if the element’s key is a book. If we replace it with the above function here’s what we’ll get:
xpath(outputs('Convert_to_XML_2'),'string(//*[local-name()="book"]/*[local-name()="author"])')
We’ll get the same author name when we run the Flow.
Common Mistakes and Solutions
Here’s the list of the most common mistakes when using this function.
Using a string
There’s a very common mistake where people use a “Compose” action or a variable to store the XML value but get the following error:
InvalidTemplate. Unable to process template language expressions in action 'Compose' inputs at line '0' and column '0': 'The template language function 'xpath' expects its first parameter to be an XML object. The provided value is of type 'String'. Please see https://aka.ms/logicexpressions#xpath for usage details.'.
Power Automate requires an XML, not a string, even if the string has a valid XML definition. To solve this problem, you need to use the XML function like this:
xpath(xml(<add string here>),...)
Another solution is to have a variable with the XML function and then use that variable in future functions and actions like this:
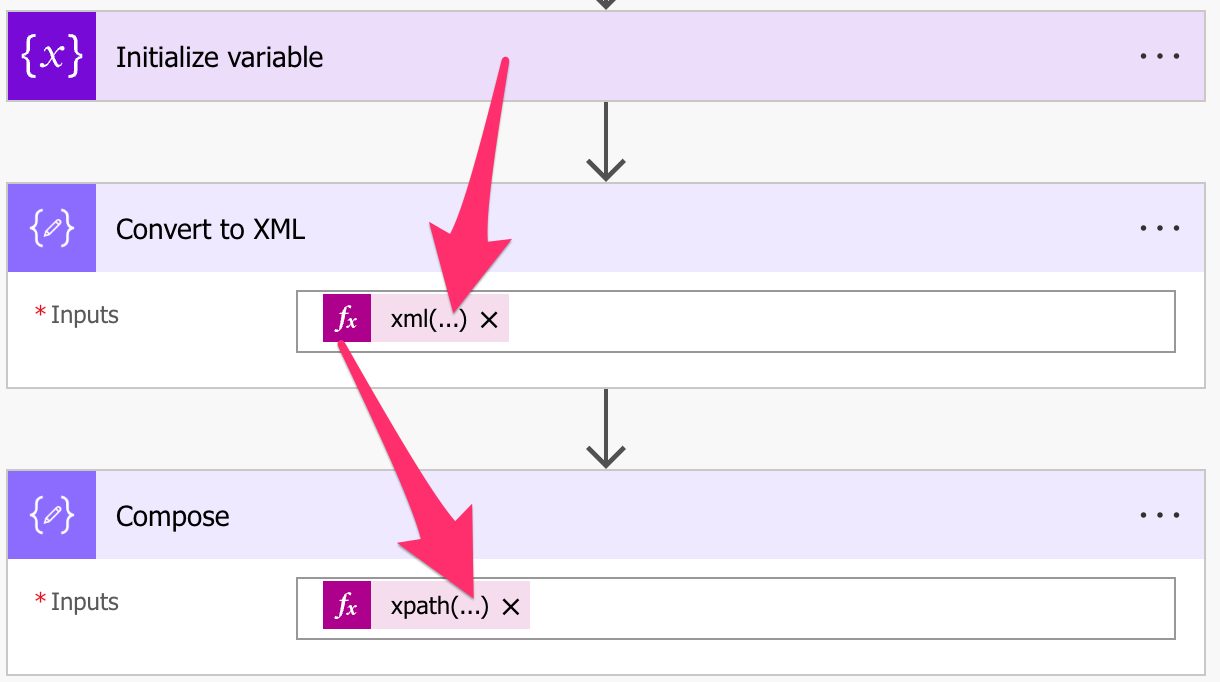
This way, you only need to do the conversion once. It’s not obvious what Power Automate does when converting this object, even when you look at the result of the action like this:
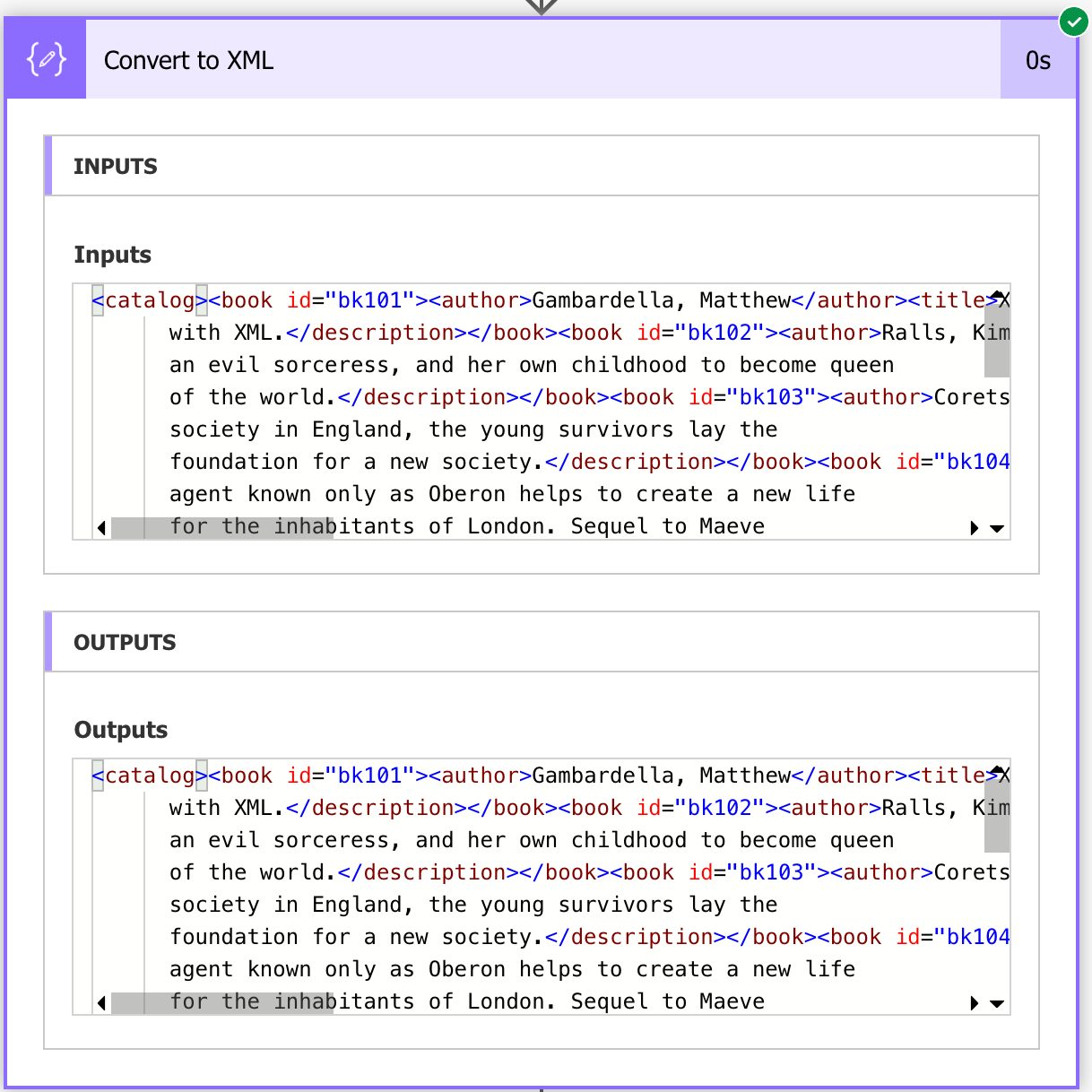
The input and outputs look the same, but they are not. Please keep this in mind.
Using / to find the information
As you’ve seen before, you have to use the “/<node>” notation to reach the data you want, but sometimes you could get the following error message:
Unable to process template language expressions in action 'Compose' inputs at line '0' and column '0': 'The template language function 'xpath' parameters are invalid: the 'xpath' parameter must be a supported, well formed XPath expression. Please see https://aka.ms/logicexpressions#xpath for usage details.'.
The expression that we used to get the following error message is this:
xpath(outputs('Convert_to_XML'),'/catalog/')
The expression is correct, but if you notice, we have an extra “/“ at the end of the “catalog”. This is considered not valid, and the correct expression should be:
xpath(outputs('Convert_to_XML'),'/catalog')
Thinking the result will be a string
The “xpath function” won’t return a string to us unless we ask it to, as we’ve seen in the first example above. If you provide the following formula:
xpath(outputs('Convert_to_XML'),'string(//catalog/book/author)')
You will get the following:
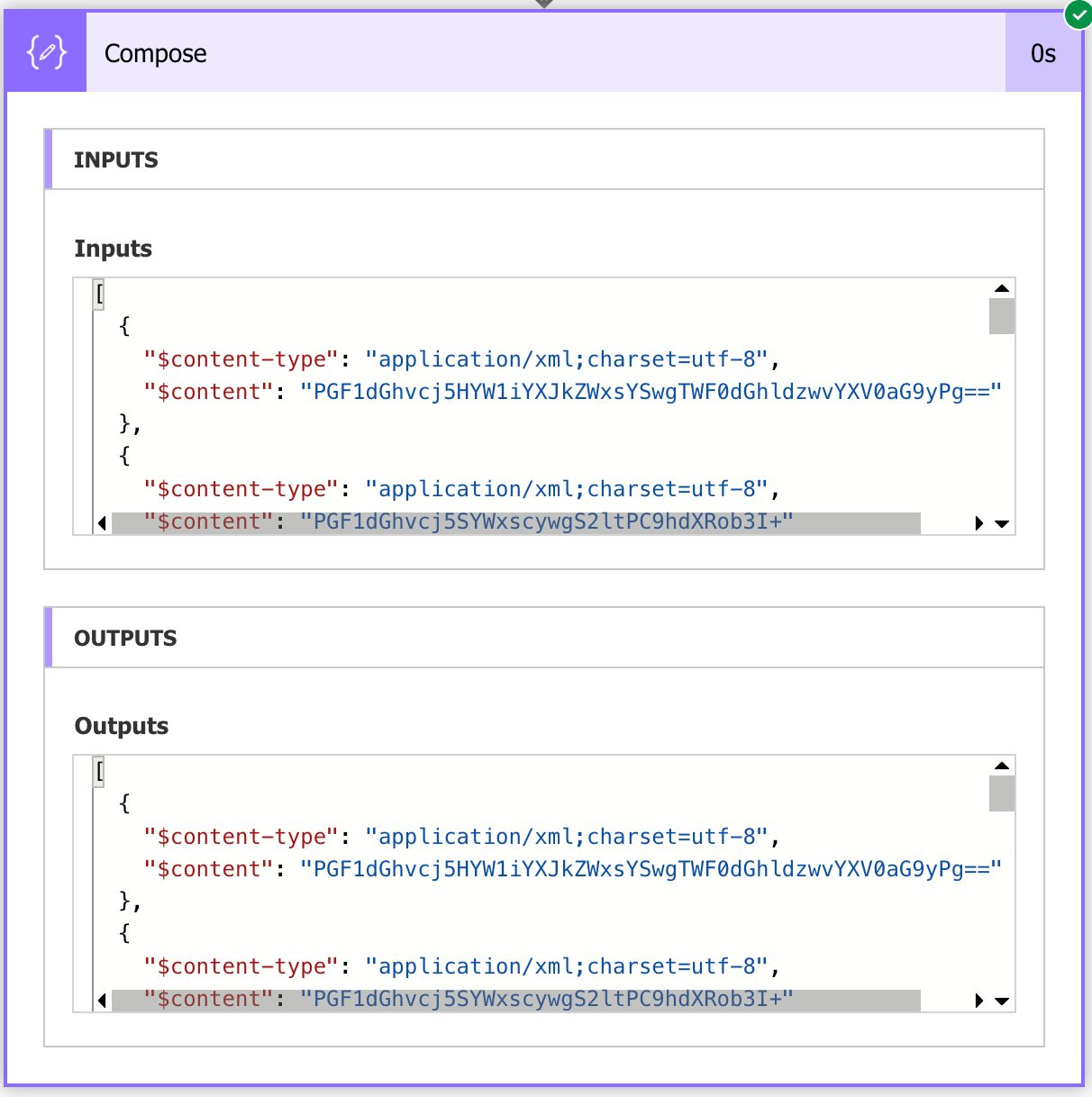
Notice that we added two forward slashes in the beginning, to indicate that we would like only the first one. But we got all of the “authors” in the XML as a base64 representation. The correct formula is the following:
xpath(outputs('Convert_to_XML'),'string(//catalog/book/author)')
And then you would get:
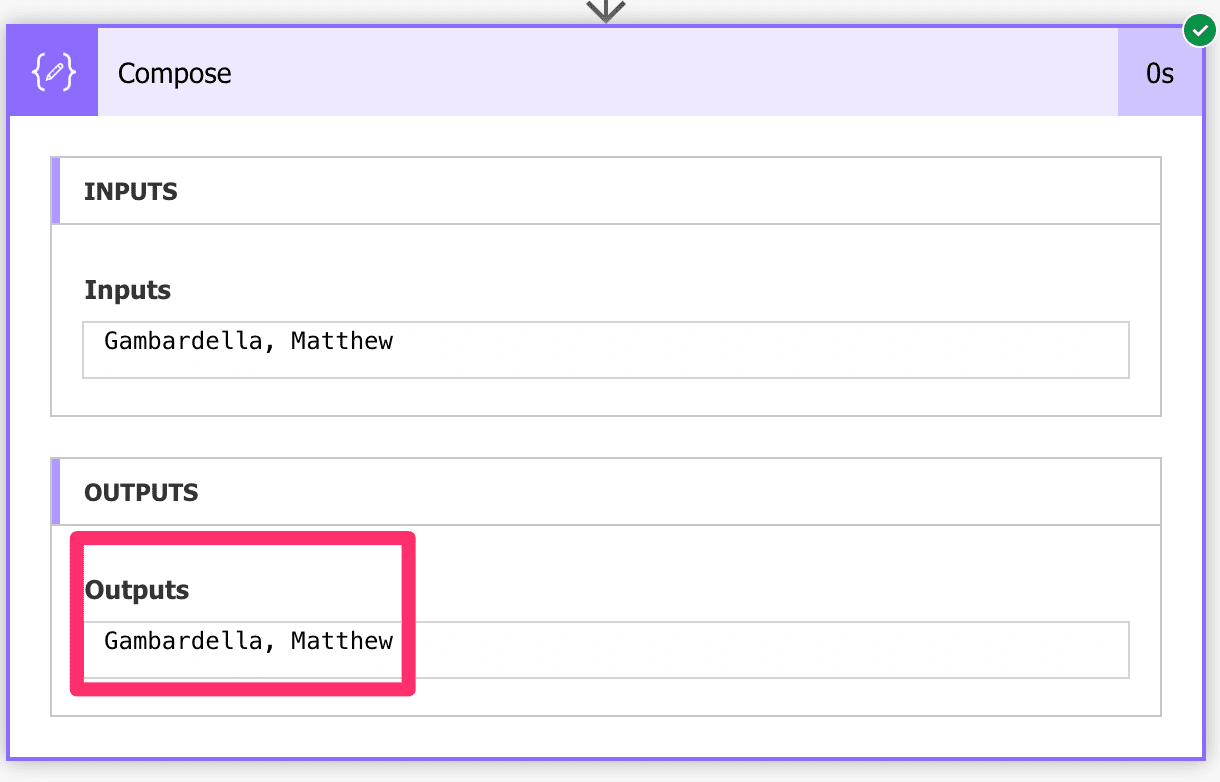
If you want to get all authors and parse them, you would need to use an “Apply to Each” action and use the same function.
Nodes are case-sensitive.
Please notice that the XML nodes are case-sensitive, meaning that “book” is not the same as “Book”. So if you don’t see the result you’re trying to find, please check if the element has the correct name.
Using single quotes
I’ve shown how to reproduce the error above, but here’s the error message:
Fix invalid expression(s) for the input parameter(s) of operation
Above, I showed you how to solve this by using single quotes like this:
xpath(outputs('Convert_to_XML'), '//book[@id = ''bk102'']')
But another alternative is to build the parameter using a variable or a “Compose” action. If you use a “Compose” action, you don’t need to worry about escaping the quotes.
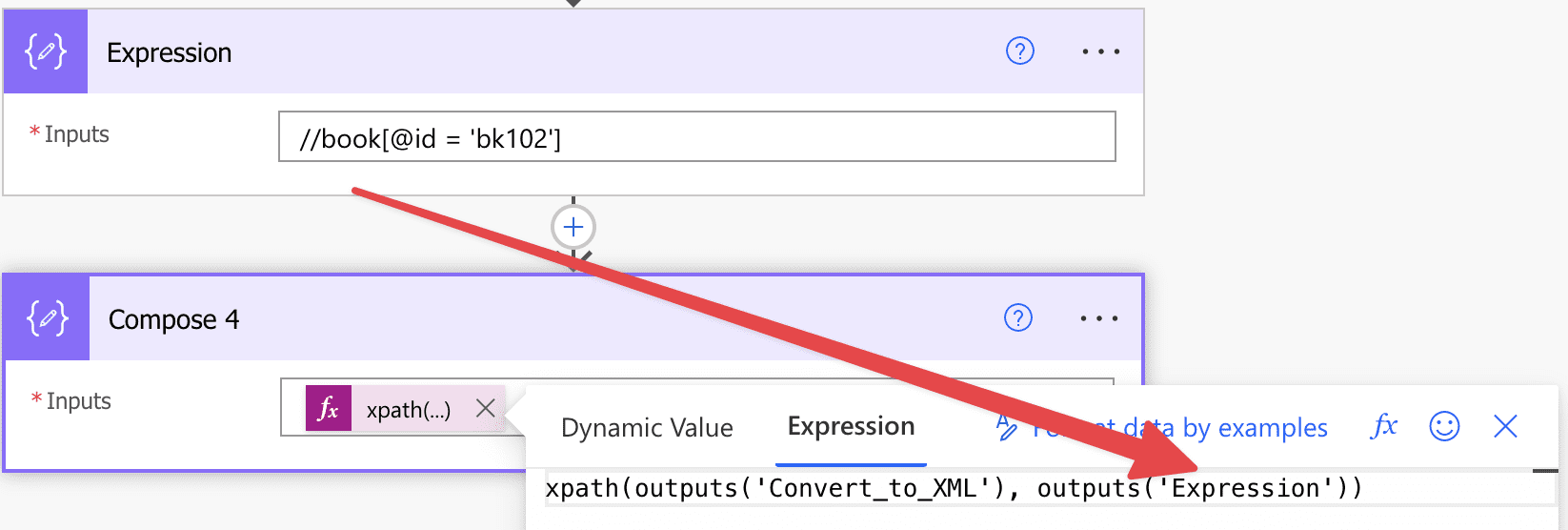
Then all you need to do is use the output in the expression, and you’re good to go.
Recommendations:
Here are some things to keep in mind.
Don’t nest
There’s no real reason to do it, but if you find yourself in a situation where you have nested not functions in a formula, you should review it and make everything more straightforward. You may run into problems, and since you can build your expression in many different ways, there’s no real advantage in how to do it.
Always add a comment.
Adding a comment will also help avoid mistakes. Indicate why you are trying to find the element and what it means. It may look obvious initially but it will not be in a few months or years. It’s essential to enable faster debugging when something goes wrong.
Sources:
Microsoft’s xpath Function Reference
Back to the Power Automate Function Reference.
Photo by Shahadat Rahman on Unsplash



Amazing article! I wish I would have found this earlier in my Power Automate journey.
I was confused by this section:
“Thinking the result with be string:
xpath(outputs(‘Convert_to_XML’),’string(//catalog/book/author)’)”
as there does not appear to be any difference in these expression…
“Notice that we added two forward slashes in the beginning, to indicate that we would like only the first one. But we got all of the “authors” in the XML as a base64 representation. The correct formula is the following:
xpath(outputs(‘Convert_to_XML’),’string(//catalog/book/author)’)”
Also, I don’t believe // selects only the First element, but rather looks for any starting point.